
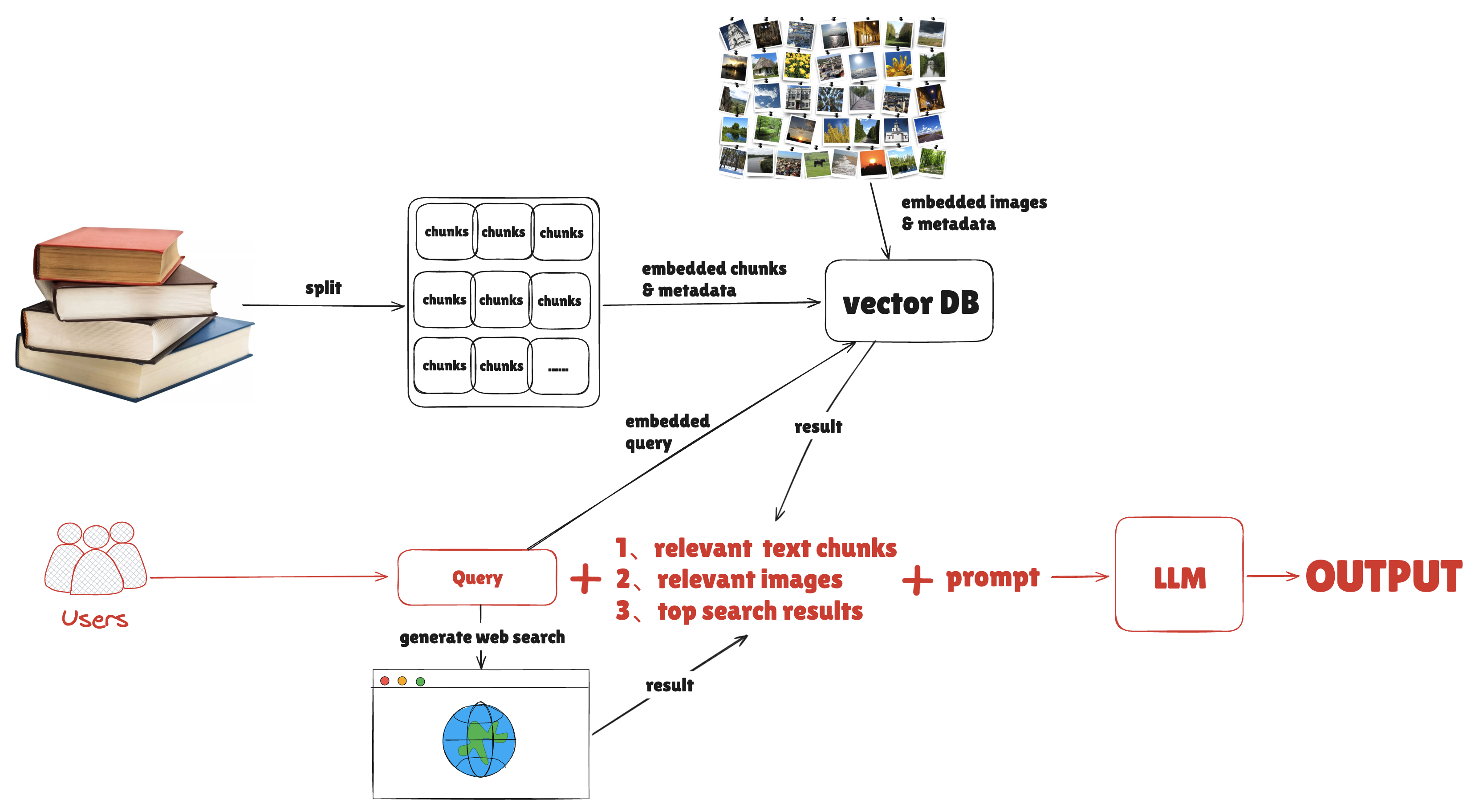
一、文本的RAG
文本RAG的核心是通过embedding model ,将文本chunks的语义进行向量化,并存储至向量数据库。
在用户实际进行检索的时候,将问题也同样进行向量化,去到向量空间内进行比对,获取最相似的几段chunk。
最终将(prompt + 相关的chunks + 问题)一起给发LLM,输出结果。
二、图片的RAG
通过多模态的embedding model将图片的含义语义化至向量空间,并存储至向量数据库。
在用户实际进行检索的时候,将问题也同样进行向量化,去到向量空间内进行比对,获取相似度最高的图片。
图片除了语义信息,还包含EXIF原数据,例如拍摄的时间、地点(经纬度)、海拔等信息。可以一起存储至向量数据库。
三、搜索的RAG
搜索的RAG本质上是调用搜索引擎获取最新的数据,其差异无非就是
有没有进行二次的处理、结构化,方便LLM处理。如 Tavily
还是就简单粗暴的将主页的内容返回。如 duckduckgo的三方库
下边我们来看具体的代码实现。