
Claude 账号被ban?教你用 AWS 免费体验 Claude 3.5 Sonnet 模型!
无需注册,Amazon Bedrock 免费体验 Claude 3.5 最新 AI 对话模型!
Amazon Bedrock 教程:三步轻松启用 Claude 3.5 Sonnet 模型!
突破 Claude 地区限制:Amazon Bedrock 提供 Claude 3.5 模型体验!
作为AI的第三世界,毫无疑问Claude肯定是不能用的。
视频内容的补充及勘误:
1、请各位领导一定注意⚠️bedrock是一种收费的备用选择,具体的定价如下:https://aws.amazon.com/cn/bedrock/pricing/
2、勘误:视频中直接拿bedrock,Google AI Studio直接与面向消费者的ChatGPT进行对比,好似关公战秦琼。实际上ChatGPT platform后台相关参数也都可以调,Claude和Gemini面向消费者的产品也都不能调。本人Temperature调的过低,导致在视频中胡说八道,特此更正。
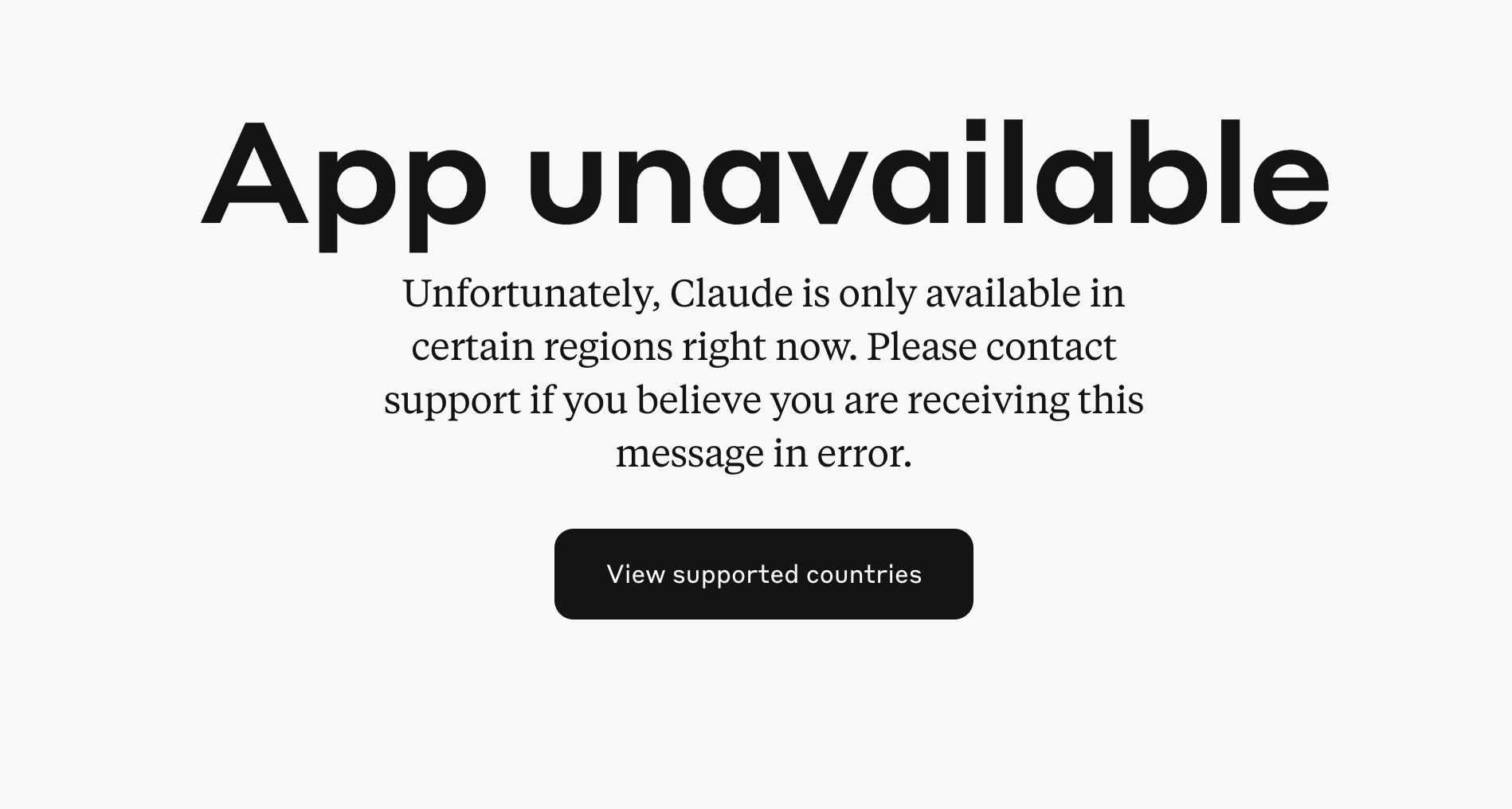
App unavailable Unfortunately, Claude is only available in certain regions right now. Please contact support if you believe you are receiving this message in error.
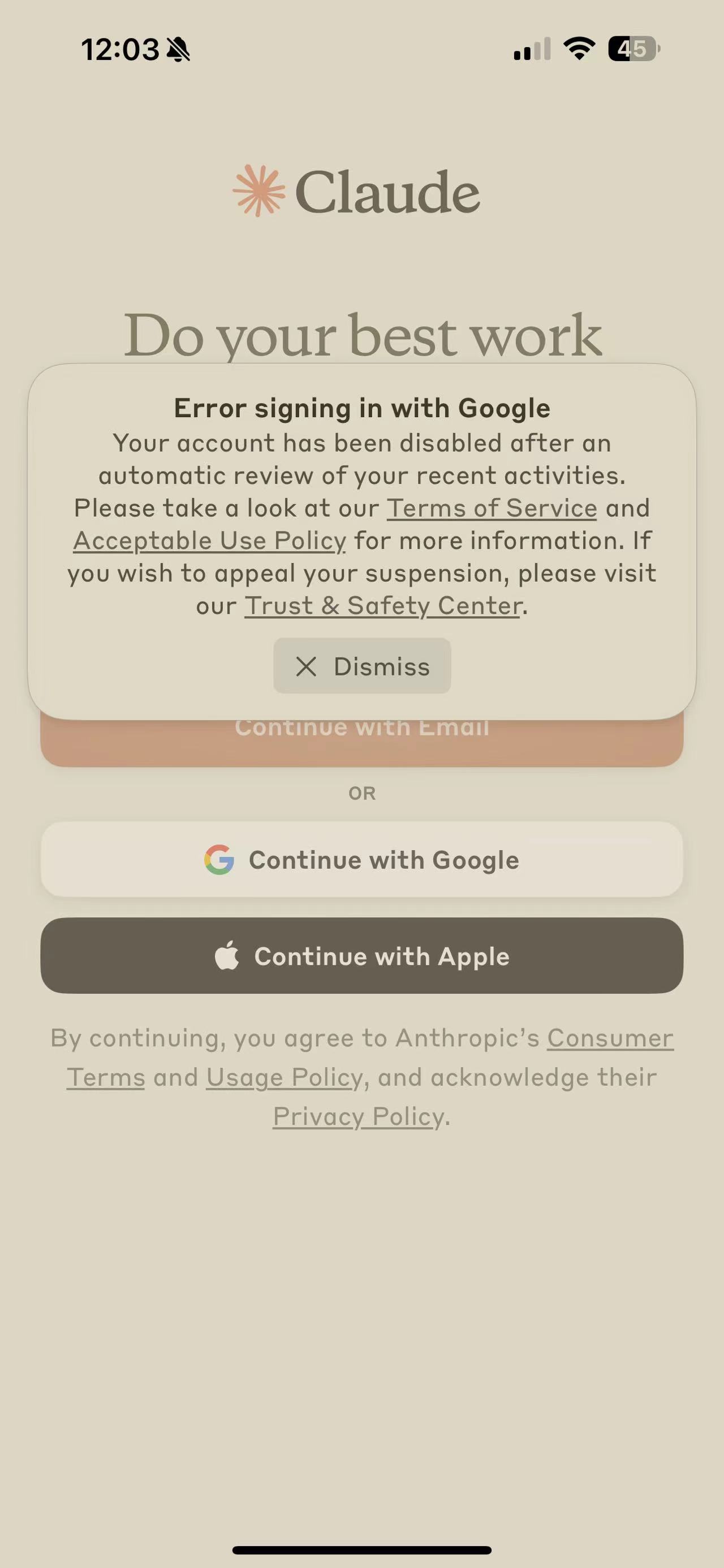
我自己用谷歌账号+接码平台注册了一个Claude的账号,但是仅仅过了一个晚上,账号就被BAN了。Error signing in with Google Your account has been disabled after anautomatic review of your recent activities.Please take a look at our Terms of Service andAcceptable Use Policy for more information.lfyou wish to appeal your suspension, please visitour Trust & Safety Center.
那如何使用Claude 3.5 Sonnet?就要用到Amazon Bedrock了。
1、前提,注册好AWS的账号,同时确保账户区域要选择美国。
假如没有选择美国的话,部分的模型可能暂未开放
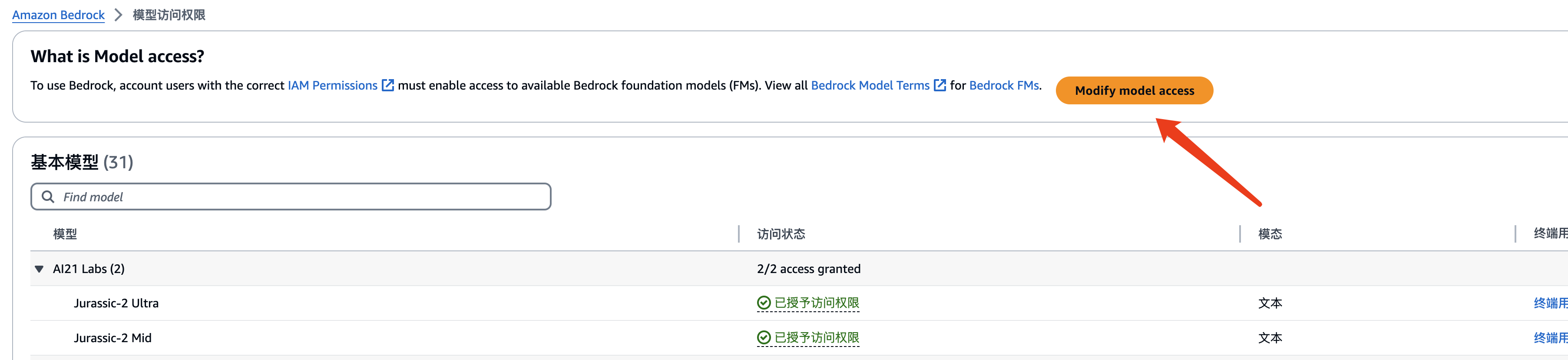
2、打开模型的支持
打开这个链接:https://us-east-1.console.aws.amazon.com/bedrock/home#/modelaccess
选择修改模型权限。
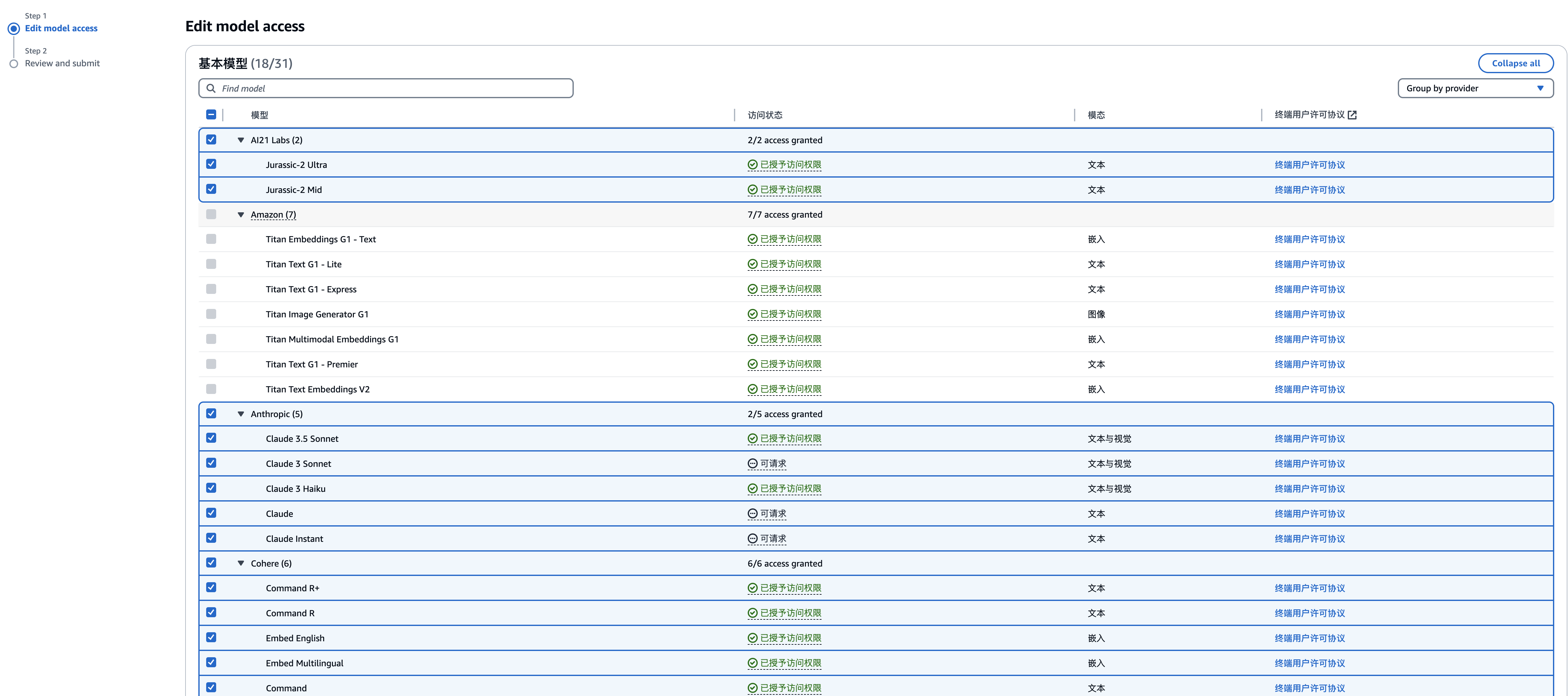
选择增加新的模型访问:
修改完成后,选择左上角搜索bedrock:
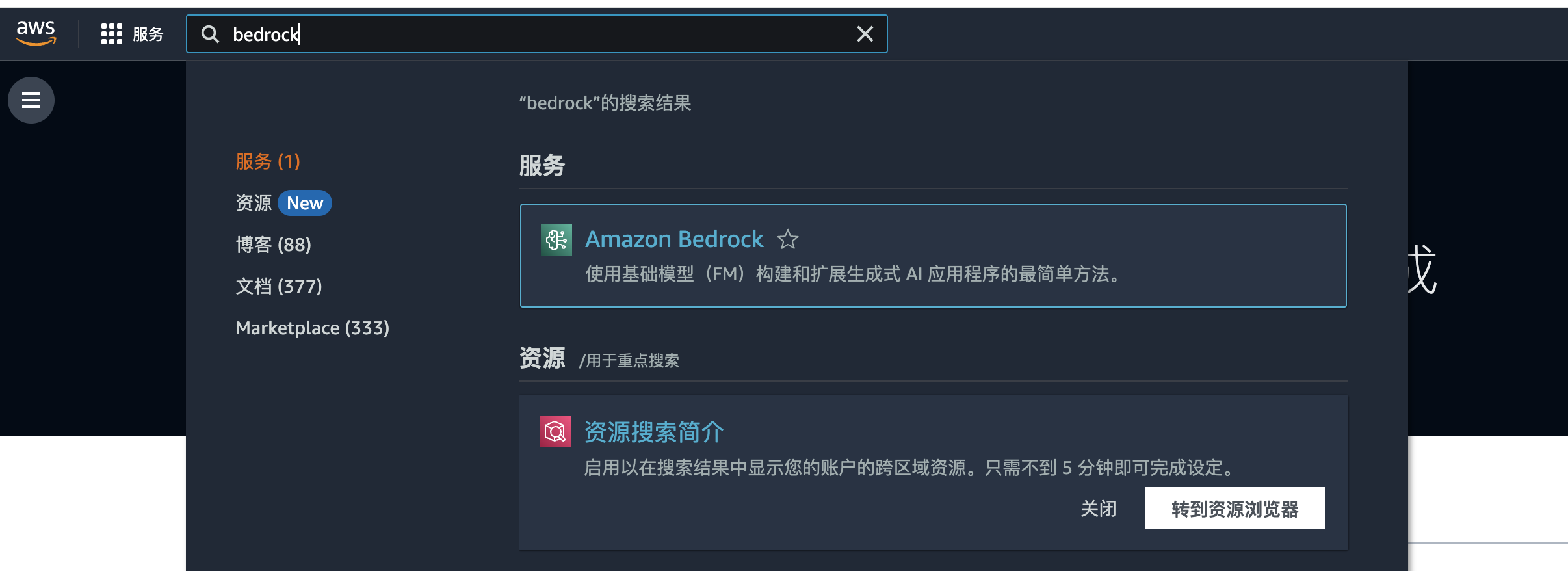
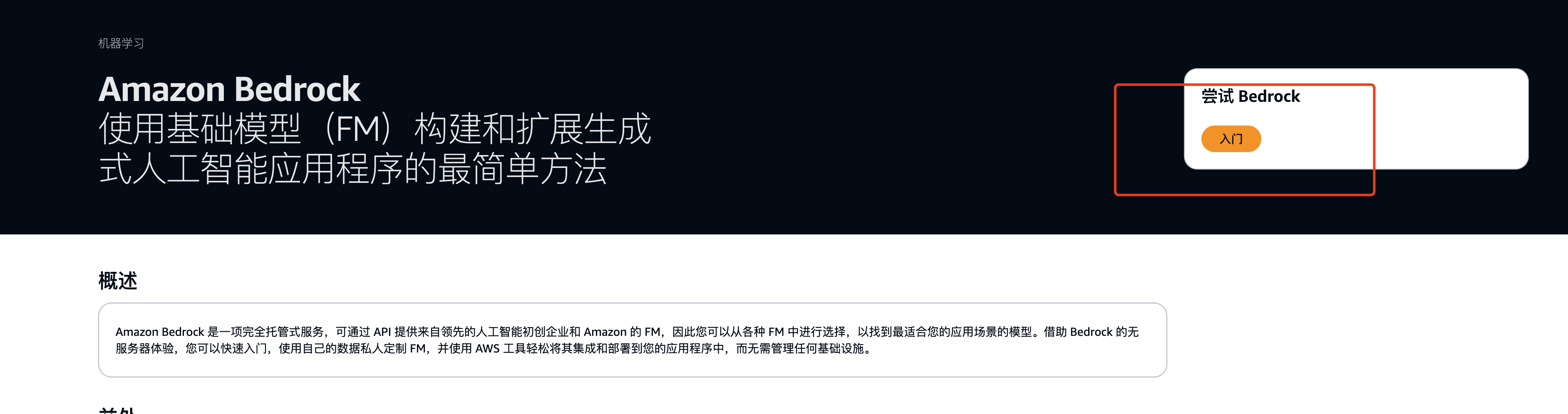
进入之后选择右上角入门:
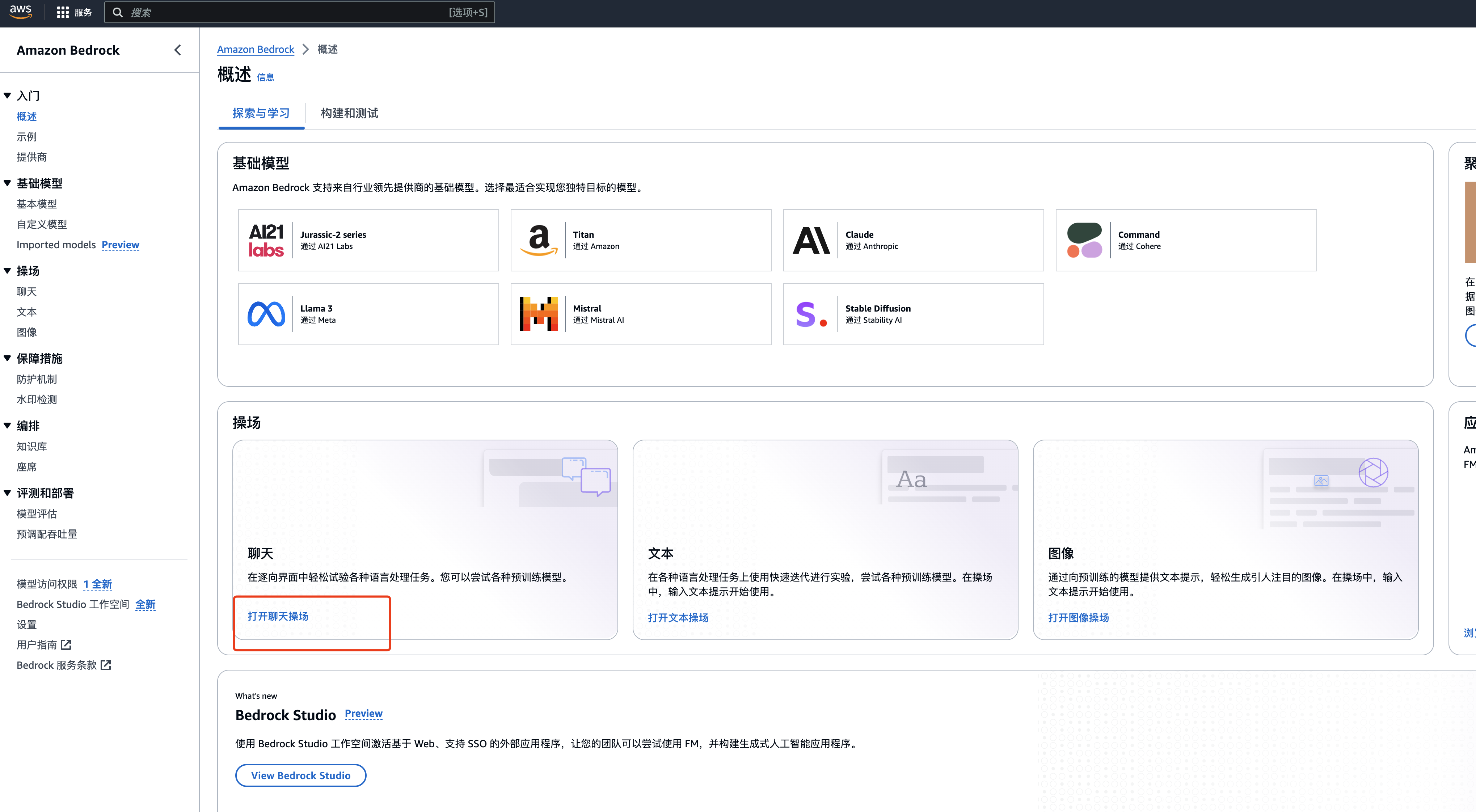
进入之后,选择打开聊天操场:
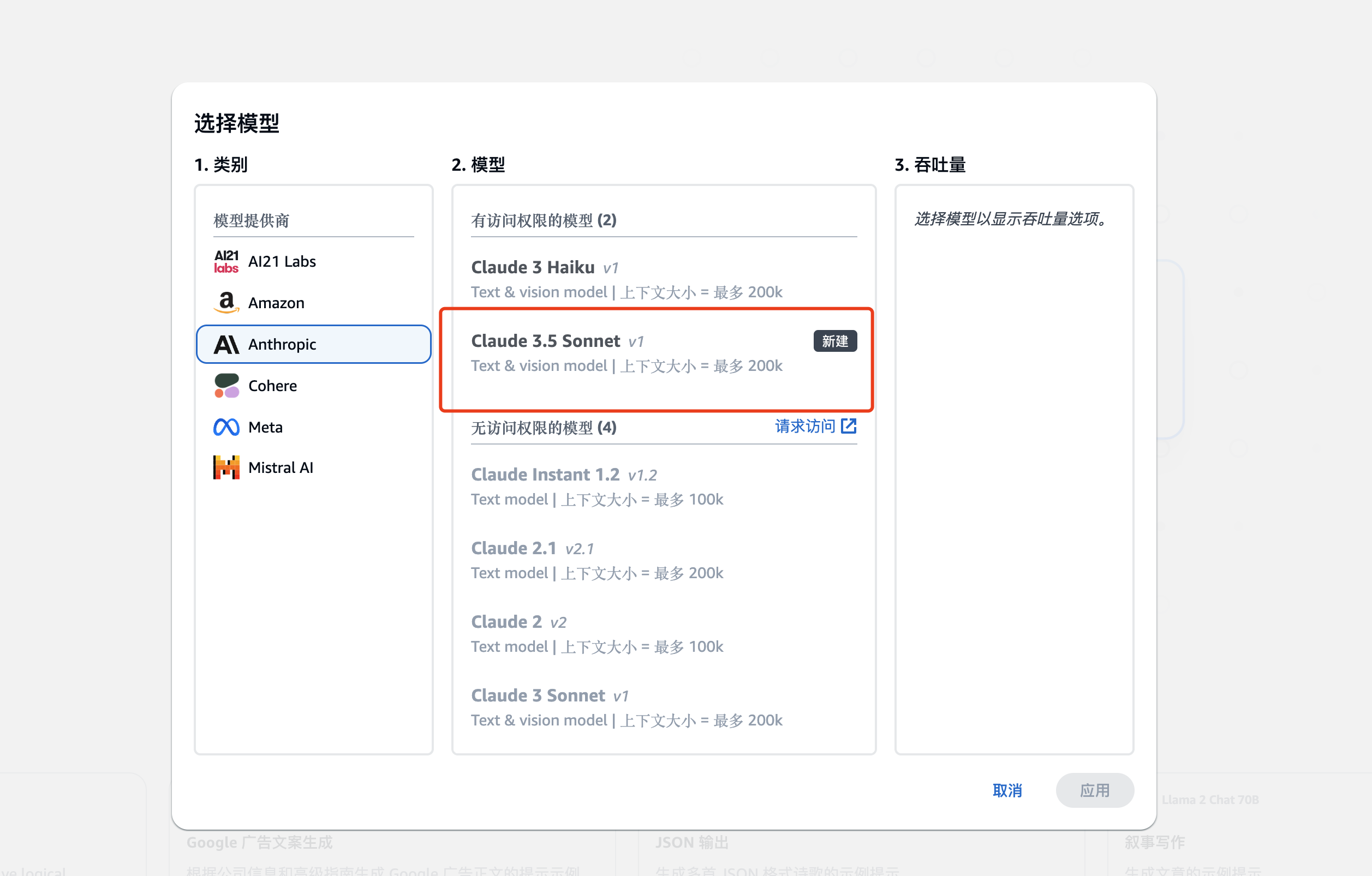
进入聊天操场之后,选择对应的模型:
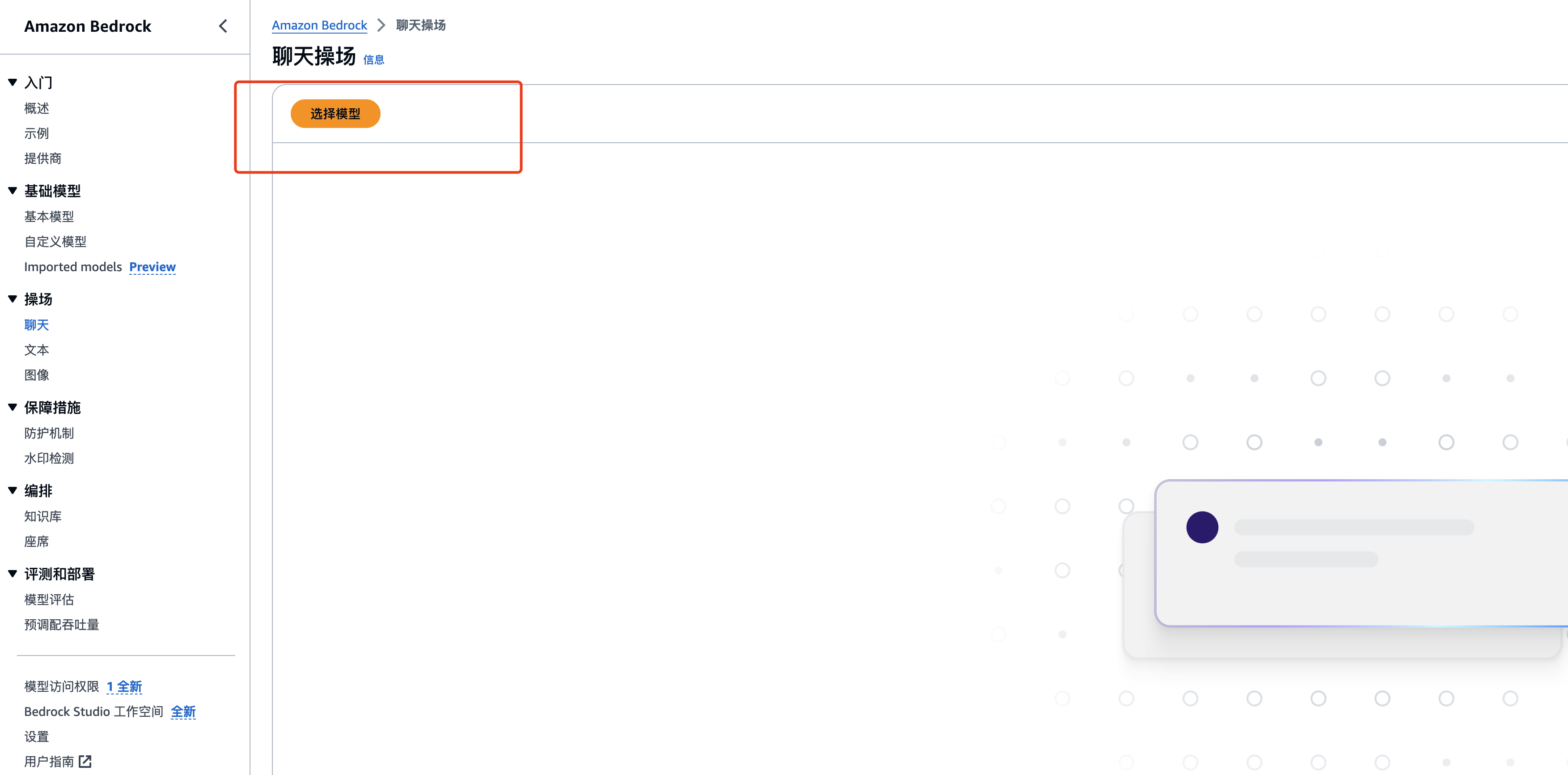
挑选模型,如Claude 3.5
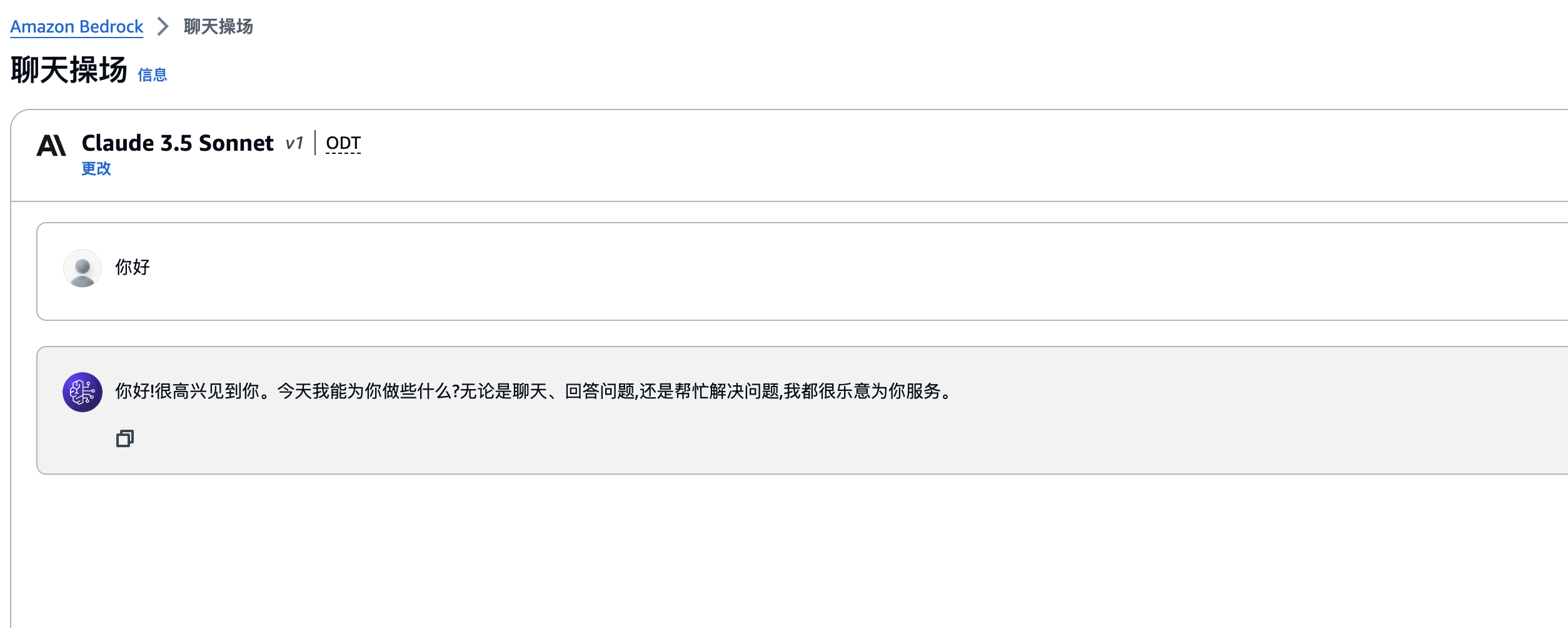
3、使用聊天操场功能正常使用即可
Top P、Top K 和 Temperature 都是用于控制语言模型输出多样性和创造性的参数。
1. Top K Sampling (Top K 采样)
含义: 从模型预测的下一个词的概率分布中,选择概率最高的 K 个词,然后在这个子集中重新采样。
作用:
限制模型的随机性: 避免模型选择概率极低的、不相关的词,使输出更合理。
控制输出的多样性: K 值越小,输出越确定,多样性越低;K 值越大,输出越随机,多样性越高。
示例: 假设 K=3,模型预测下一个词的概率分布为:
"the": 0.5
"a": 0.3
"beautiful": 0.1
"quickly": 0.05
"jumping": 0.05
Top K 采样会从 "the", "a", "beautiful" 中随机选择一个词作为输出。
2. Top P Sampling (Top P 采样,也称为 Nucleus Sampling)
假设 P=0.8,模型预测下一个词的概率分布如下:
"the": 0.5
"a": 0.3
"beautiful": 0.1
"quickly": 0.05
"jumping": 0.05
Top P 采样会按照以下步骤选择候选词:
排序: 首先,按照概率从高到低对词语进行排序: "the", "a", "beautiful", "quickly", "jumping".
计算累积概率: 依次计算每个词的概率与其前面所有词概率的累加值(即累积概率):
"the": 0.5
"a": 0.5 + 0.3 = 0.8
"beautiful": 0.8 + 0.1 = 0.9
"quickly": 0.9 + 0.05 = 0.95
"jumping": 0.95 + 0.05 = 1.0
确定候选词: 从排序后的词语列表中,找到累积概率首次大于等于 P(0.8) 的位置。 在这个例子中,"a" 的累积概率为 0.8,达到了 P 值,因此 "the" 和 "a" 会被选中作为候选词。 "beautiful" 及其之后的词语会被排除,因为它们的累积概率已经超过了 P 值。
最终采样: 最后,模型会从候选词 ("the" 和 "a") 中随机选择一个作为最终输出。
3. Temperature (温度)
含义: 用于缩放模型预测的概率分布。
作用:
控制输出的创造性: 温度越高,概率分布越平坦,模型更可能选择低概率的词,输出更具创造性,但也可能更不准确;温度越低,概率分布越尖锐,模型更可能选择高概率的词,输出更准确,但也可能更平淡。
示例: 假设 Temperature=1.2,模型预测下一个词的概率分布同上。
温度会放大低概率词的相对概率,使得模型更有可能选择 "beautiful", "quickly" 或 "jumping" 等词。
参数选择建议:
一般情况下,建议使用 Top P 采样,并设置 P 值在 0.8-0.9 之间。 这可以提供较好的多样性和一致性平衡。
如果需要更具创造性的输出,可以尝试提高 Temperature 值。 但需要注意,温度过高可能会导致输出不连贯。
Top K 采样可以作为一种更直接地控制输出多样性的方式。 但需要根据实际情况选择合适的 K 值。
希望以上解释能够帮助你理解 Top P、Top K 和 Temperature 参数的含义和作用。