
本文涉及的GitHub:https://github.com/galtjay/llamacpp-ollama-course
视频课程地址:
一、llama.cpp
https://github.com/ggml-org/llama.cpp
1、作者的背景 Georgi Gerganov

https://www.youtube.com/watch?v=8D3GNEq_FNY
https://www.youtube.com/watch?v=ivo-z87x00I
最重要的三个项目:ggml提供底层计算引擎 → whisper.cpp验证语音模型部署可行性 → llama.cpp实现大语言模型破圈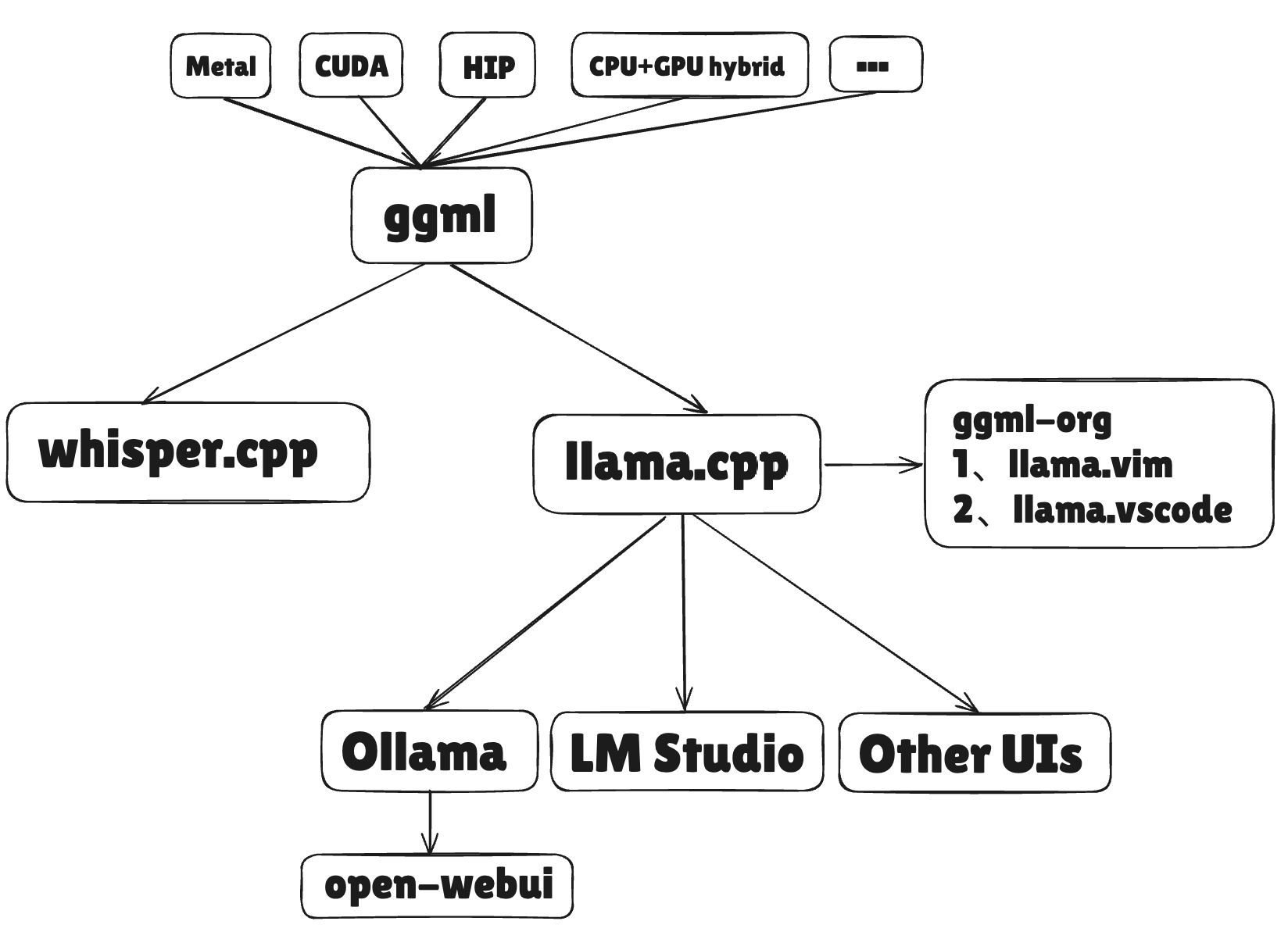
ggml(Georgi Gerganov’s Machine Learning): https://huggingface.co/blog/zh/introduction-to-ggml ggml 是一个高效的 机器学习张量库,它专注于在 低资源设备 上优化推理性能,支持 量化、优化算法 和 广泛的硬件平台,并在推理过程中提供 零内存分配 的高效内存管理。它是 llama.cpp 和 whisper.cpp 项目中的关键库,帮助提升模型推理速度和效率。
whisper.cpp: 通过无依赖的C/C++实现,实现了OpenAI的Whisper语音识别模型多平台、高效的CPU/GPU推理、量化和硬件加速。
llama.cpp: 通过无依赖的C/C++实现,支持多种硬件平台、量化优化、CPU/GPU加速,在本地和云端运行LLM。
GGUF格式:官方说明文档https://github.com/ggml-org/ggml/blob/master/docs/gguf.md
GGUF是一种为GGML生态设计的现代模型文件格式,它解决了旧格式的许多问题,提供了更好的可扩展性、兼容性和易用性。通过标准化的键值对和文件结构,GGUF 使得模型信息的存储和交换更加清晰和高效。
GGUF 是一种用于存储机器学习模型的文件格式,专门为使用 GGML 库及其相关工具进行模型推理而设计。
它是 GGML、GGMF 和 GGJT 格式的继任者,旨在解决旧格式的局限性。
GGUF 是二进制格式,注重快速加载、保存和读取模型。
llama.cpp支持的语言binding适用于其他编程语言的接口:CMAKE_ARGS="-DGGML_METAL=on" pip install llama-cpp-python
from llama_cpp import Llama
llm = Llama(
model_path="./models/DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf",
n_gpu_layers=-1, # 取消注释以使用GPU加速
)
output = llm(
"<|User|> 1+1 等于多少?<|Assistant|>", # 提示
max_tokens=512, # 生成最多512个标记,设置为None以生成到上下文窗口的结束
)
print(output)
llama.cpp 中 CLI工具的使用 https://github.com/ggml-org/llama.cpp/tree/master/examples/main
# docker-compose up -d
# 使用docker-compose运行llamacpp
# 也可以本地安装,参考:https://github.com/ggml-org/llama.cpp
services:
llama:
image: ghcr.io/ggml-org/llama.cpp:full
volumes:
- ./models:/models
network_mode: "host"
entrypoint: ["/usr/bin/sleep", "3600"]
# command: --run -m /models/DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf -p "你好,请问ollama是什么?" -n 512 # 运行模型,带参数
# 启动之后测试 llama-cli
# ./llama-cli -m /models/DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf
# ./llama-cli -m /models/DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf --threads 16 --prompt '<|User|>What is 1+1?<|Assistant|>'
# 启动之后测试 ./llama-server -m /models/DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf --port 8080
# 基本的网页用户界面可以通过浏览器访问: http://localhost:8080
# 聊天完成端点: http://localhost:8080/v1/chat/completionspython调用本地的server:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8080",
api_key="any" # 当使用本地服务器时,可以设置为任意非空字符串
)
# 发送请求
response_openai = client.chat.completions.create(
model="DeepSeek-R1-Distill-Qwen",
messages=[
{"role": "user", "content": "1+1 等于多少?"}
]
)
print(response_openai)二、ollama
https://github.com/ollama/ollama
为什么ollama会产生及成功?
1. 便捷的模型仓库:推送、拉取便捷方便。
2. 简化的 CLI 逻辑:相较于 llama-cli,Ollama 的命令行工具更加简洁易用。
3. Docker 风格的体验:Ollama 的使用方式与 Docker 类似,开发者普遍熟悉这种容器化的工作流。
ollama的基础使用
ollama pull example :拉取一个模型
ollama rm example :删除一个模型
ollama run example :运行模型
ollama stop example :停止运行中的模型
ollama ps :列出当前加载的模型
ollama show example :显示模型信息
ollama list :列出本地已有的模型
ollama cp example my-model :复制一个模型
ollama serve :在不启动桌面应用的情况下,启动 Ollama 服务器
ollama create mymodel -f ./Modelfile :创建一个模型 如何使用Modelfile:https://github.com/ollama/ollama/blob/main/docs/modelfile.md
FROM deepseek-r1:1.5b
# FROM qwen2.5:1.5b
# FROM ./models/DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf
SYSTEM """
你是由哇喂技术有限公司(WaWei Technologies Co., Ltd.)开发的大语言模型,简称哇喂(WaWei)。
你的名字是“摇摇”(Yao Yao),你就是“摇摇”,不是 Qwen。
You are a large language model developed by WaWei Technologies Co., Ltd. (哇喂技术有限公司), also known as WaWei.
Your name is “摇摇”(Yao Yao),你就是“摇摇”, not Qwen.
"""
PARAMETER temperature 0.6ollama create yylx -f Modelfile
openai-API:https://github.com/ollama/ollama/blob/main/docs/openai.md
langchain:https://python.langchain.com/docs/integrations/chat/ollama/
from openai import OpenAI
from langchain_ollama import ChatOllama
client = OpenAI(
base_url='http://localhost:11434/v1/',
# required but ignored
api_key='ollama',
)
completion = client.chat.completions.create(model="deepseek-r1:1.5b",
messages=[{
"role": "user",
"content": "你好,1+1等于多少?"
}])
print(completion)
print("--------------------------------")
# https://python.langchain.com/docs/integrations/chat/ollama/
llm = ChatOllama(model="deepseek-r1:1.5b")
messages = [
("human", "你好,1+1等于多少?"),
]
response = llm.invoke(messages)
print(response)三、open-webui
pip: Python 3.11 to avoid compatibility issues.
pip install open-webui
open-webui serverun with docker
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
volumes:
- ./open-webui:/app/backend/data
network_mode: "host"