
近期DeepSeek大模型的热度持续攀升,用户激增导致服务器频繁过载,这一现象不仅影响了用户体验,也反映出云端服务的局限性。
面对高并发访问压力,本地私有化部署方案应运而生。私有化部署具备双重核心优势:❶全程离线运行确保数据绝对安全,支持本地知识库个性化集成❷完全免费使用,彻底规避服务器响应延迟问题。
第一步:跨平台工具Ollama的下载与模型部署指南
Ollama作为开源的大模型管理框架,支持在主流操作系统上运行包括DeepSeek在内的多种AI模型。访问官网下载页面获取对应版本安装包:
https://ollama.com/download
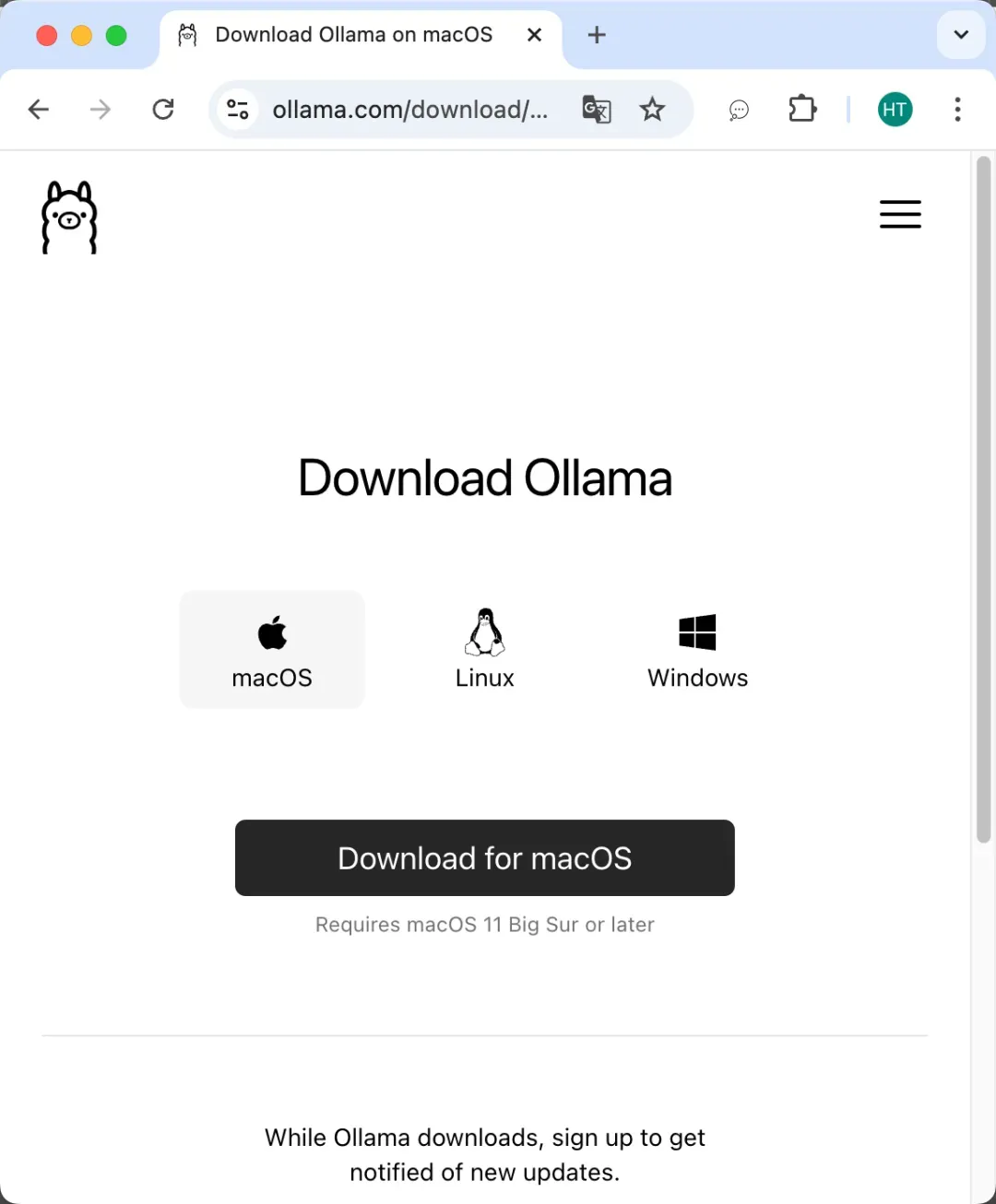
Mac用户下载dmg文件后,建议将程序图标拖拽至Applications目录以便管理。Windows用户需注意安装包体积较大,建议预留足够存储空间。

启动终端执行模型拉取指令时,DeepSeek-R1提供从1.5B到70B多个版本选择。建议配置32GB以上内存设备尝试14B以上版本,64GB内存设备可运行70B完整版。
ollamarundeepseek-r1:70B
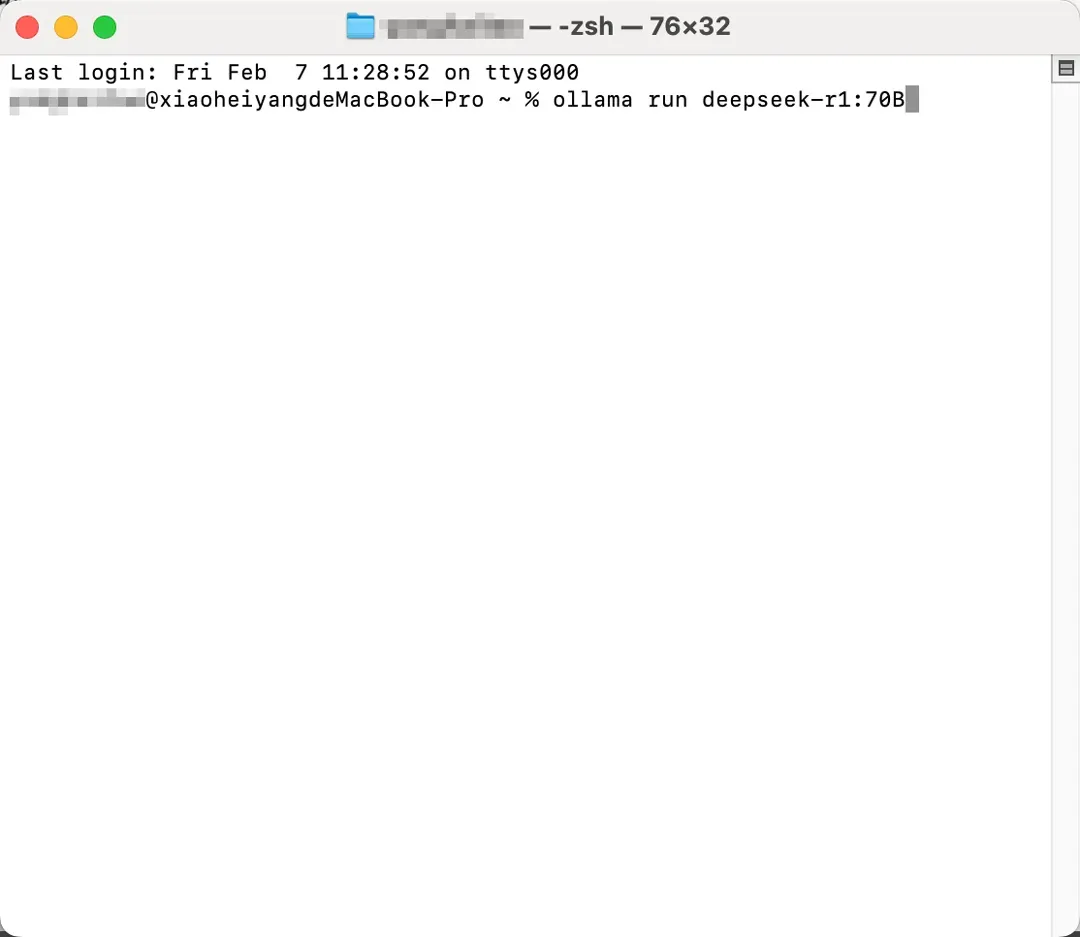
模型下载过程中需注意网络稳定性,70B版本约42GB的体量需要较长时间传输。完成部署后可通过命令行界面进行基础交互,系统会实时显示模型的推理过程和最终输出结果。

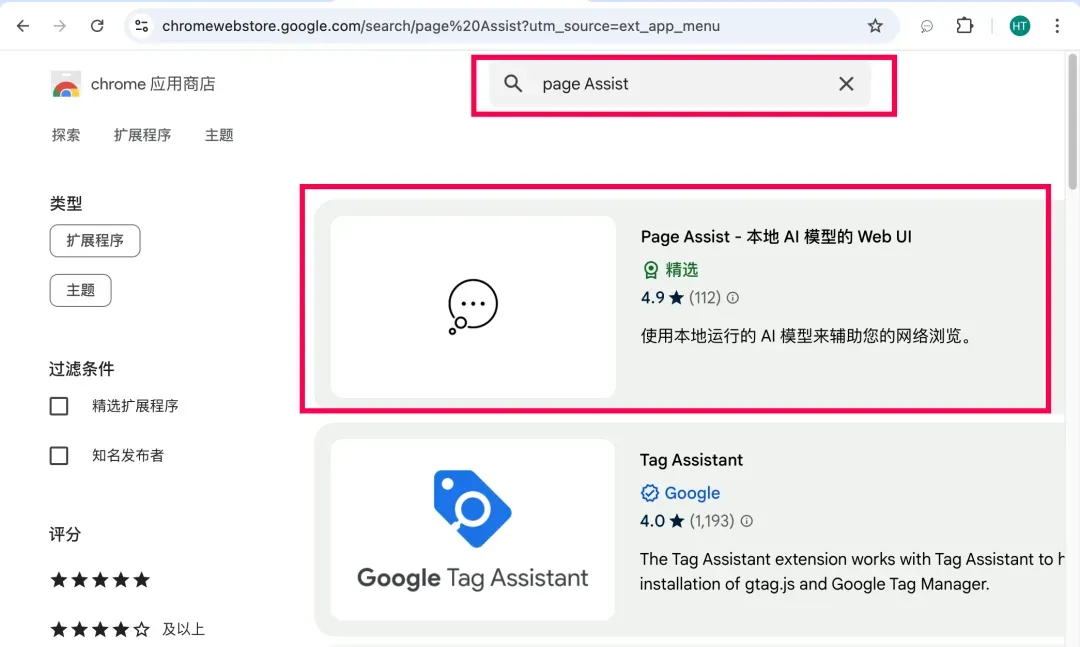
第二步:可视化交互工具Page Assist的配置与优化
通过Chrome扩展商店安装Page Assist插件,该工具可将命令行交互转换为可视化操作界面。安装完成后在浏览器工具栏激活插件,即可看到已部署的模型列表。
高级设置中建议调整以下参数:
- 界面语言切换为简体中文
- 启用本地知识库集成功能
- 配置搜索引擎增强模块
- 调整推理线程数优化性能
多平台部署专项指南
Windows系统注意事项
选择exe安装包时需确认系统架构版本,建议配备NVIDIA显卡设备开启CUDA加速。1.5B轻量版适合入门体验,但响应质量有限。
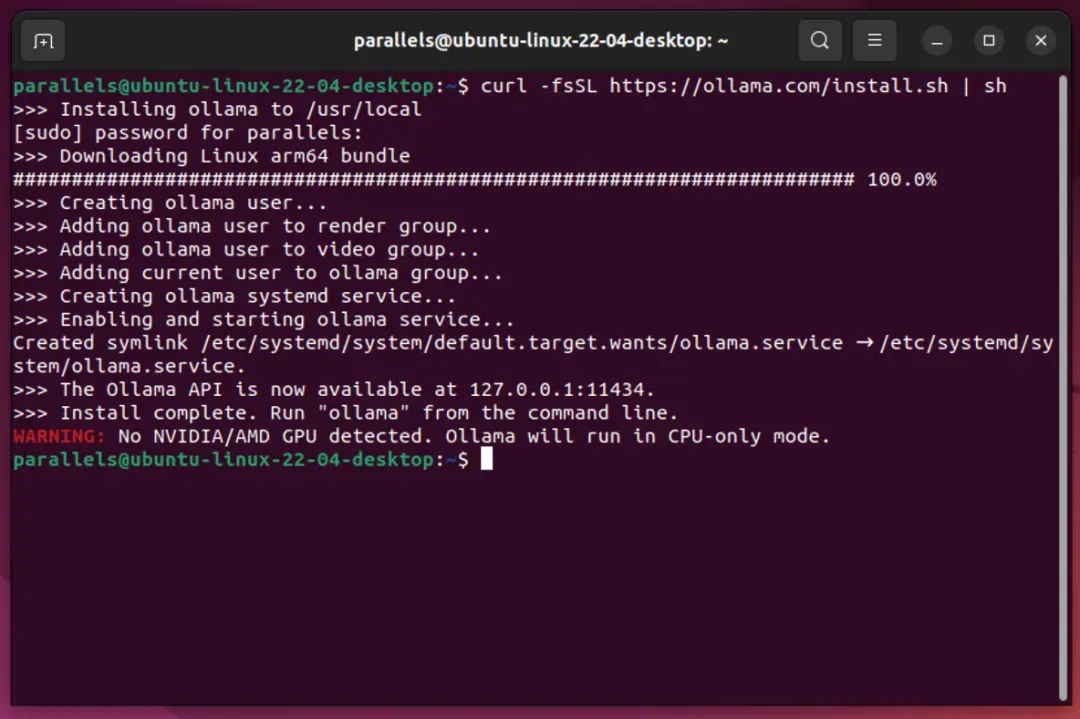
Linux系统快速部署
通过终端执行自动化安装脚本,建议Ubuntu 22.04以上版本。部署完成后可通过systemd服务实现开机自启。
curl -fsSL https://ollama.com/install.sh | sh
移动端使用建议
虽然理论上支持手机部署1.5B版本,但考虑到硬件损耗与使用体验,建议通过API接口调用云端服务。国内多个主流AI平台均可提供替代方案。

硬件配置参考标准
- 入门级:16GB内存+集成显卡可运行7B以下模型
- 进阶级:32GB内存+RTX3060显卡建议选择14B版本
- 专业级:64GB内存+多显卡交火可流畅运行70B模型
实际测试显示,70B模型在96GB内存设备运行时,复杂任务场景下CPU负载可达80%以上,建议做好散热管理。
通过本方案实现本地化部署后,用户可永久免费使用DeepSeek各项功能,且支持自定义训练专属模型。对于企业级部署需求,可关注后续发布的集群部署专题教程。