
缓存、消息队列、以及分库分表是高并发解决方案中不可或缺的重要组成部分。
缓存能够显著提高系统性能,其核心原因在于以下两个方面:
- 降低 CPU 消耗
通过将需要实时计算的内容预先计算,复用一些常用的数据,能够有效减少 CPU 的负担,从而提高响应速度。
- 降低 I/O 消耗
将对网络、磁盘等较慢存储介质的读写操作转变为对内存等高速介质的访问,进一步提升系统响应效率。
在应用系统中,我们通常将缓存分为本地缓存和分布式缓存。
本地缓存:这种缓存组件与应用程序共享同一进程,读写速度极快且没有网络延迟。然而,由于各个应用或集群节点需要维护独立的缓存,无法实现缓存共享。
分布式缓存:这种缓存组件与应用程序相分离,多个应用可以直接共享缓存,增强了缓存的使用灵活性和容量。
本文将深入探讨本地缓存与分布式缓存的不同之处,帮助读者在面对各种业务场景时,做出合理的缓存选择。
一、本地缓存的实现与应用
JDK Map的使用
JDK中的Map常常用于实现本地缓存,主要有以下几种类型:
- HashMap:基于哈希表的集合类,提供快速的插入、查找和删除操作,适合用作缓存项的存储。
- ConcurrentHashMap:线程安全的HashMap,适合在多线程环境中进行高效的读写操作。
- LinkedHashMap:有序的HashMap,能够保留元素的插入顺序,提供按顺序遍历的能力。
- TreeMap:基于红黑树的有序Map,支持按键的顺序遍历。
在我曾负责的艺龙红包系统中,红包活动信息存储在ConcurrentHashMap中,并通过定时任务进行缓存刷新。
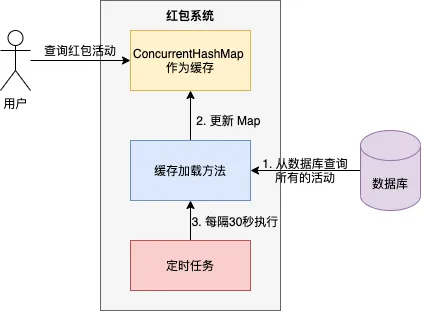
核心流程:
- 系统启动时,初始化一个ConcurrentHashMap用于存储红包活动缓存;
- 从数据库中查询所有红包活动信息,并存储于Map中;
- 每30秒执行定时任务,刷新缓存。
为什么选择将红包活动信息存储在本地内存的ConcurrentHashMap中呢?
- 红包系统是一个高并发应用,能够快速响应用户请求,显著提升用户体验;
- 红包活动数量有限,将其全部存储在Map中并不会导致内存溢出;
- 定时任务的缓存刷新不会对红包系统的业务造成影响。
许多单体应用选择这样的方案,因其简单易用,工程实现相对容易。
本地缓存框架
尽管使用JDK Map可快速构建缓存,但其功能较为单一,难以满足现实场景需求。因此,本地缓存框架应运而生。
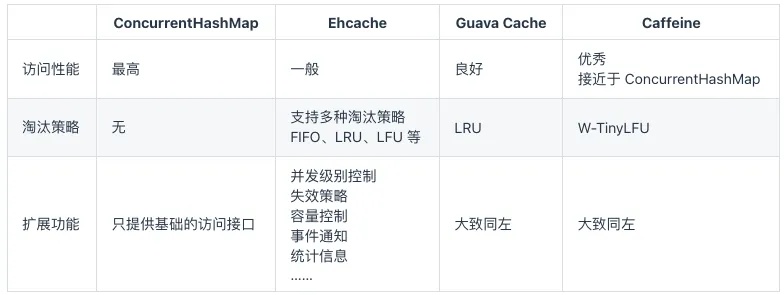
流行的Java缓存框架包括:Ehcache、Google Guava和Caffeine Cache。
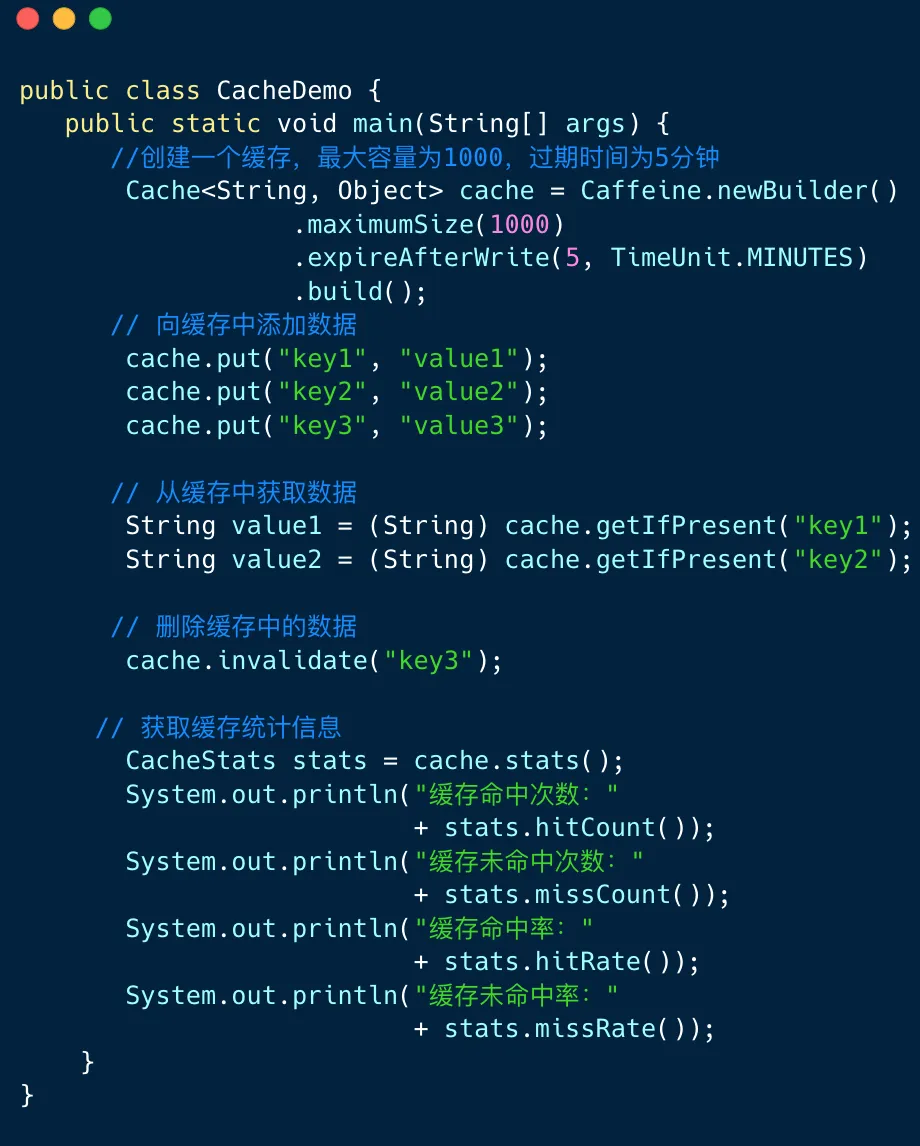
下图展示了Caffeine框架的使用实例。
尽管本地缓存框架的功能强大,但其缺点仍然显著:
- 在高并发场景中,当应用重启后,本地缓存会失效,导致系统负载增加,恢复时间较长;
- 每个应用节点维护独立缓存,缓存同步存在一定难度。
二、分布式缓存的应用
分布式缓存将缓存数据分散在多台机器上,从而提高缓存容量和并发读写能力。通常由多台机器组成一个集群,每台机器运行相同的缓存服务进程,缓存数据均匀分布在各个节点。
在分布式缓存中,Redis是最受欢迎的选择,很多后端工程师首推它。
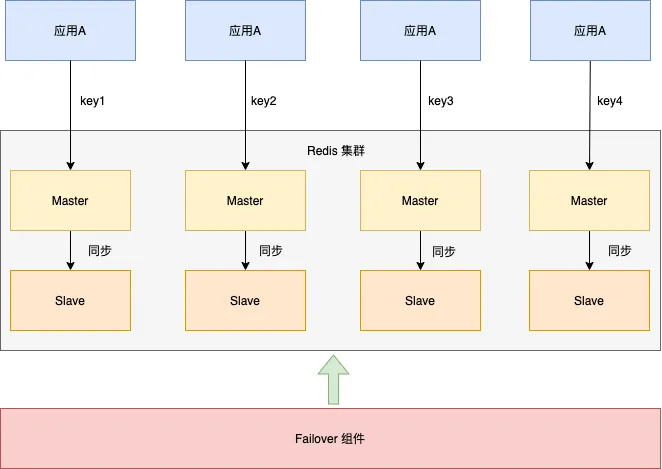
下图展示了神州专车的Redis集群架构。将Redis集群分为四个分片,每个分片包含一主一从,主从可以切换。应用A根据不同的缓存key访问不同的分片。
与本地缓存相比,分布式缓存具有以下优势:
1、扩展性与性能
通过增加集群中的机器数量,可以扩展缓存的容量和并发读写能力,同时所有缓存数据对应用都是共享的。
2、高可用性
由于数据分布在多台机器上,即使某台机器出现故障,缓存服务也能持续提供服务。
但分布式缓存的缺点也不可忽视:
1、网络延迟
分布式缓存通常需要通过网络进行数据读写,可能会出现响应时间相对较长的问题。
2、复杂性
分布式缓存需要考虑序列化、数据分片和缓存大小等问题,相比于本地缓存,配置和管理更为复杂。
以下是一个真实案例,令我对分布式缓存的理解上升到新的层次。
在2014年,同事开发了一个比分直播系统,所有请求都从分布式缓存Memcached中获取。正常情况下,从缓存中获取数据非常迅速,但随着在线用户稍微增加,整个系统的性能却显著下降。
通过jstat命令观察发现GC频率极高,几次请求后新生代便会被占满,CPU消耗主要集中在GC线程上。问题的根源在于缓存值过大,数据显示缓存大小在300k到500k之间。
解决方案经过两个步骤:
- 调整新生代大小,由原来的2G增大到4G,并精简缓存数据大小(从平均300k降到80k);
- 将缓存拆分为两部分,一部分为全量数据,另一部分为增量数据(数据量较小)。初次请求拉取全量数据,比分变化时通过websocket推送增量数据。
经过优化,性能有了显著提升,平均响应时间在5ms左右。起初我认为问题出现的可能性很小,但某夜突然发现app首页显示的数据时有不同。
这表明:尽管LoadingCache线程在持续更新缓存信息,各台服务器的本地缓存数据并不一致,揭示了两个重要问题:
- 惰性加载可能导致多台机器数据不一致;
- LoadingCache线程池配置不当,导致线程堆积。
最终,我们的解决方案是:
- 结合惰性加载与消息机制更新缓存数据:当导购服务配置变动时,通知业务网关重新拉取数据,更新缓存。
- 适当增加LoadingCache的线程池参数,并监控线程池使用情况,确保在忙碌时能够发出警报并动态调整参数。
三、多级缓存的策略
开源中国最初使用本地缓存框架Ehcache,但随着访问量激增,面临“Java程序更新频繁,每次更新后都需重启,本地Ehcache缓存数据被清空,重启后若有大量访问,数据库将迅速崩溃”的问题。
因此,开源中国开发了多级缓存框架J2Cache,结合了本地缓存Ehcache与分布式缓存Redis,具有以下优势:
- 离用户越近,速度越快;
- 减少分布式缓存查询频率,降低序列化与反序列化的CPU消耗;
- 大幅度减少网络I/O及带宽消耗。
本地缓存作为一级缓存,分布式缓存作为二级缓存。首先从一级缓存查询数据,如有则直接返回;若未查询到,则从二级缓存获取,再将数据回填至一级缓存和二级缓存;若二级缓存也未查询到,则从数据源获取,将结果分别回填至一级和二级缓存中。
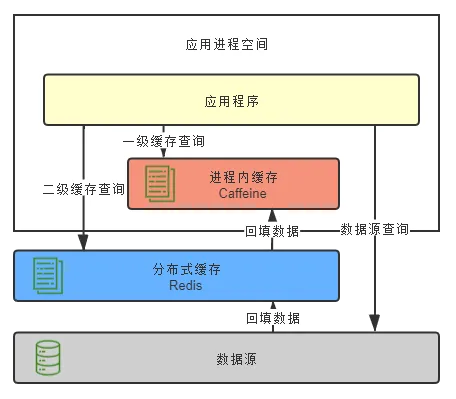
在2018年,我服务的一家电商公司需要对app首页接口进行性能优化。经过两天的努力,完成了整个方案,采用的是两级缓存模式,同时利用Guava的惰性加载机制,整体架构如下图所示:
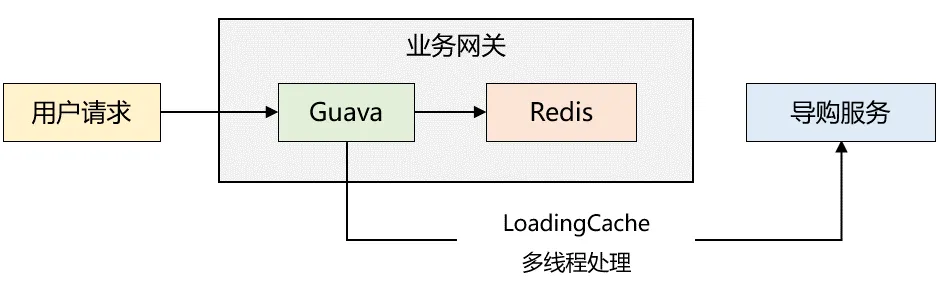
缓存读取流程如下:
- 业务网关启动时,若本地缓存无数据,读取Redis缓存,若Redis缓存同样为空,便通过RPC调用导购服务获取数据,接着将数据存入本地缓存和Redis;若Redis缓存不为空,则将缓存数据写入本地缓存。
- 由于步骤1已对本地缓存进行预热,后续请求直接从本地缓存读取,返回给用户端。
- Guava配置了刷新机制,每隔一段时间调用自定义的LoadingCache线程池(最大5个线程,5个核心线程),同步数据至本地缓存和Redis中。
经过优化,性能表现良好,平均响应时间保持在5ms左右。起初我认为问题出现的几率很小,但有一天晚上,突然发现app端首页数据时有时无。
这表明:虽然LoadingCache线程在不断更新,但各台服务器的本地缓存数据并未完全一致,揭示了两个重要的点:
- 惰性加载可能造成多台机器数据不一致;
- LoadingCache线程池数量配置不合理,导致线程堆积。
最终的解决方案为:
- 结合惰性加载与消息机制更新缓存数据:导购服务配置变动时,通知业务网关重新拉取数据,更新缓存。
- 适当调整LoadingCache的线程池参数,并监控线程池使用情况,动态调整参数以应对忙碌时段。
四、总结
Fred Brooks在1987年发表的经典论文**《没有银弹:软件工程的本质性与附属性工作》**中提到,真正的“银弹”并不存在,也就是说没有任何技术或方法能够在短期内显著提升软件工程的生产力。
通俗而言:在技术领域并没有一种通用的解决方案能够解决所有问题。技术的本质在于解决问题,而每个问题都有其独特的环境和限制条件,因此没有一种通用的技术或工具能够完美应对所有挑战。
缓存是一把双刃剑,一方面能够显著提升系统性能,另一方面也会增加系统复杂度,因为需要考虑缓存的失效、更新和一致性等问题。
在进行缓存选择时,务必要结合业务场景、研发效率、运维成本、人力资源和技术能力等因素,做出合理的决策。