
前段时间,我分享了关于阿里淘天和快手一面面试的经验,附带了详细的参考答案。今天将为大家分享来自武汉理工大学一位同学的招银网络一面面经,同样包含了超详细的参考答案,供大家查漏补缺,针对性地提高自己的短板。
招银网络的一面相对简单,面试问题主要集中在几个重要且高频的基础知识点,项目相关问题较少。而在二面时,面试官会更关注你的项目经验。

许多同学认为基础问题的考察意义不大,实际上它们在日常开发中非常重要。例如,线程池的拒绝策略及其核心参数配置,如果你不熟悉这些内容,在实际项目中使用线程池可能会遇到问题。基础问题往往是最易准备的,而深层次的底层原理、系统设计、场景题以及对项目的深度挖掘则是最具挑战性的。
自我介绍的关键要点
自我介绍通常是你与面试官的首次正式交流。换位思考,作为面试官,你想听到求职者怎样介绍自己呢?显然,不会是简单地说自己喜欢编程或是闲聊自己的兴趣。
一个优秀的自我介绍应包含以下几点:
- 简洁明了地阐述自己的技术栈和擅长领域;
- 强调自己尤其擅长的地方和优势;
- 突出自己的能力,例如对定位bug的强大能力。
自我介绍不需死记硬背,掌握要点即可,面试时可根据公司的情况灵活发挥。建议准备两份自我介绍,一份给HR,强调你的经历,简单概述编程技术;另一份给技术面试官,详细阐述技术细节和项目经验。
项目中的Dubbo通信协议
协议是两个网络实体进行通信的基础。它规定了网络中数据的传输内容和格式。
在Dubbo2中,通常使用Dubbo协议(指的是Dubbo2默认协议)加上自定义序列化(如Hessian2、ProtoBuf、Kryo、FST)。
<!-- 协议使用 Dubbo,序列化使用Kryo -->
<dubbo:protocol name="dubbo" serialization="kryo"/>
<!-- 协议使用 Dubbo,序列化使用FST -->
<dubbo:protocol name="dubbo" serialization="fst"/>
Dubbo协议的格式如下:

以下是协议字段的简要说明:
- 0-15(Magic - Magic High & Magic Low):魔数,用于判断是否为Dubbo协议;
- 16(Req/Res):标识请求或响应,1表示请求,0表示响应;
- 17(2 Way):仅在请求时有效,用于标记是否期望从服务器返回值;
- 18(Event):表示是否为事件消息,比如心跳事件;
- 19-23(Serialization ID):标识序列化类型的数字;
- 24-31(Status):标识响应状态,类似HTTP状态;
- 32-63(Request ID):请求ID;
- 64-95(Data Length):内容长度;
- 96-?(Variable Part):序列化内容。
可以看出,Dubbo协议的设计相对紧凑,由头部和内容组成。头部占用96字节,后续内容为序列化后的数据,默认使用Hessian2序列化方式。
在编写RPC框架时,可以参考Dubbo协议的格式。Triple协议是Dubbo3推出的主力协议,完全兼容gRPC协议,支持各种通信模型,可以在HTTP/1和HTTP/2上运行,允许直接使用curl或浏览器访问后端Dubbo服务。

Triple协议为Dubbo协议的升级版本,解决了在跨语言、云原生和网关代理等方面的互通性问题。Dubbo框架专注于Triple协议的实现,同时对底层的网络通信、HTTP/2协议解析等依赖经过长期检验的网络库。
BIO、NIO、AIO和IO多路复用的理解
BIO(阻塞I/O)
BIO属于同步阻塞IO模型。在此模型中,应用程序发起read调用后,会一直阻塞,直到内核将数据拷贝到用户空间。
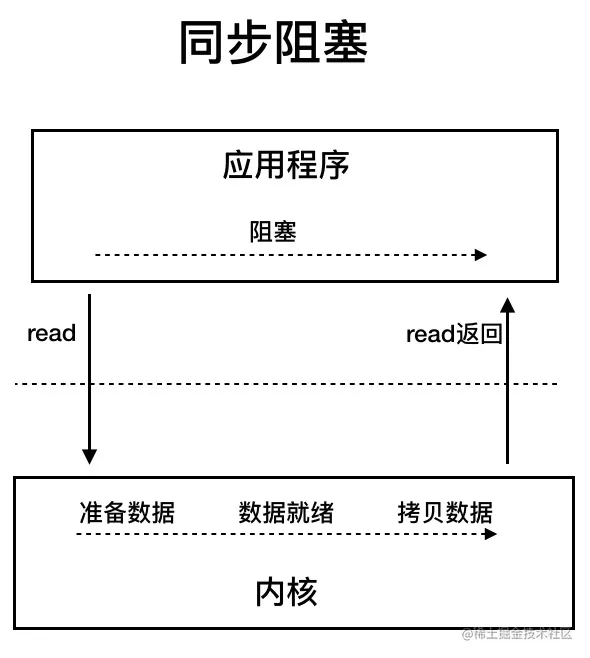
在客户端连接数量不高时,这种模型没问题,但在面对大量连接时,传统的BIO模型将无法应对,因此需要更高效的I/O处理模型。
NIO(非阻塞I/O)
Java中的NIO在Java 1.4中引入,提供了Channel、Selector、Buffer等抽象。NIO的“N”可以理解为非阻塞,不仅是新模型。它支持基于缓冲的、基于通道的I/O操作,对于高负载、高并发的网络应用,应优先使用NIO。
NIO被认为是I/O多路复用模型。
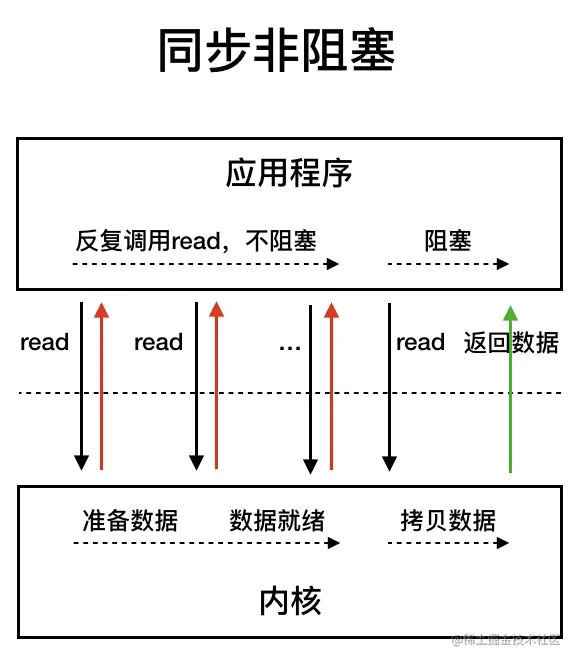
在同步非阻塞IO模型中,应用程序会一直发起read调用,直到在内核将数据拷贝到用户空间,这段时间内线程仍会阻塞。
尽管有所改进,但该模型仍存在问题:应用程序不断进行I/O系统调用以轮询数据准备状态,消耗大量CPU资源。
此时,I/O多路复用模型应运而生。
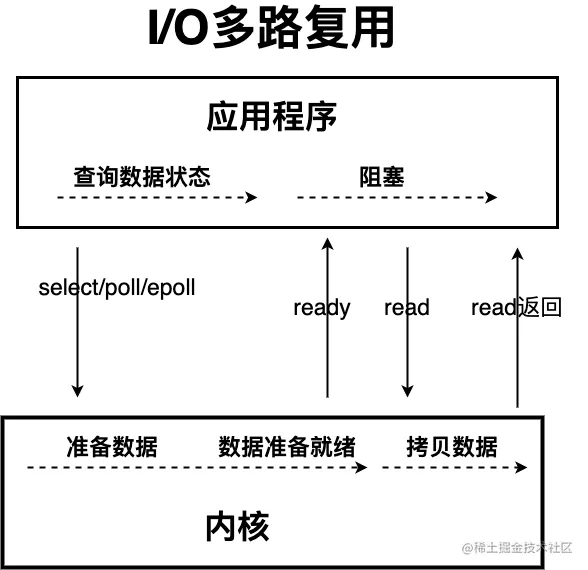
在I/O多路复用模型中,线程首先发起select调用,询问内核数据是否准备就绪,等内核准备好数据后,再发起read调用。read过程仍是阻塞的。
目前支持I/O多路复用的系统调用有select、epoll等。
- select调用:内核提供的系统调用,支持一次查询多个系统调用的可用状态;
- epoll调用:Linux 2.6内核,属于select调用的增强版本,优化了I/O的执行效率。
Java中的NIO引入了非常重要的选择器(Selector)概念,允许一个线程管理多个客户端连接。只有在客户端数据到达时,才会为其提供服务。
Buffer、Channel和Selector三者之间的关系
AIO(异步I/O)
AIO即NIO 2,Java 7中引入的异步IO模型。它基于事件和回调机制实现,应用操作后直接返回,不会阻塞,后台处理完成后,操作系统会通知相应线程进行后续操作。
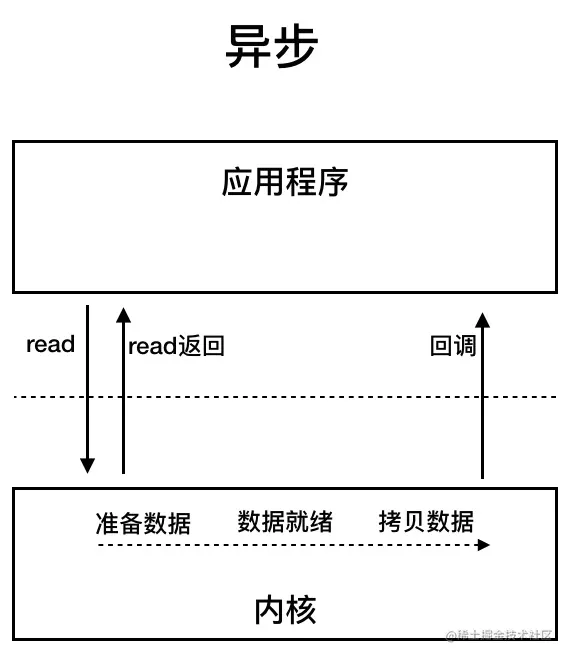
目前,AIO并不广泛应用。尽管Netty曾尝试使用AIO,但因在Linux系统上性能提升不明显而放弃。
TCP三次握手与四次挥手
建立连接 - TCP三次握手:
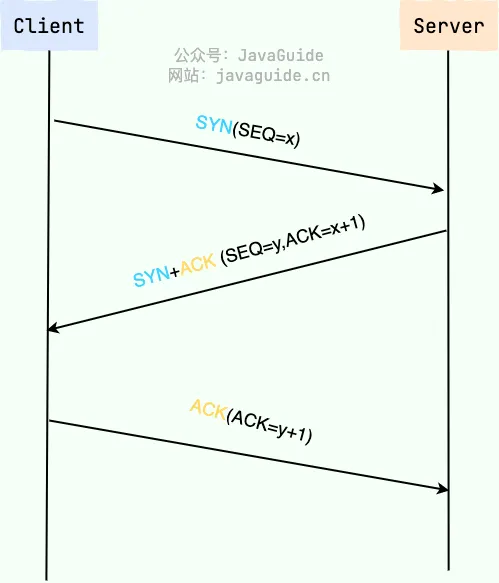
建立一个TCP连接需要“三次握手”,缺一不可:
- 第一次握手:客户端发送带有SYN(SEQ=x)标志的数据包到服务端,客户端进入SYN_SEND状态,等待服务器确认;
- 第二次握手:服务端发送带有SYN+ACK(SEQ=y, ACK=x+1)标志的数据包到客户端,服务端进入SYN_RECV状态;
- 第三次握手:客户端发送带有ACK(ACK=y+1)标志的数据包到服务端,客户端和服务端都进入ESTABLISHED状态,完成TCP三次握手。
三次握手后,客户端和服务端可以传输数据。
断开连接 - TCP四次挥手:
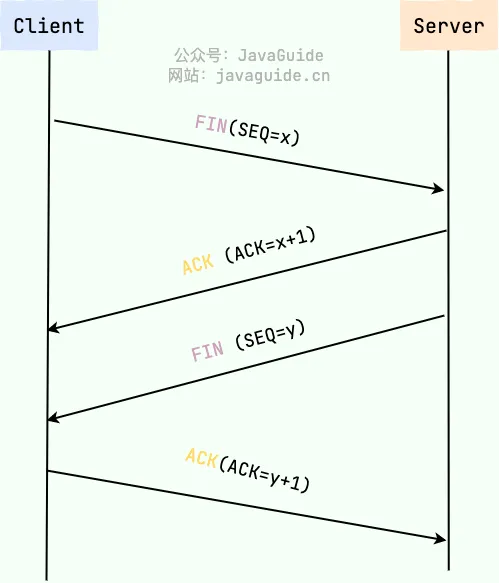
断开TCP连接则需要“四次挥手”,缺一不可:
- 第一次挥手:客户端发送FIN(SEQ=x)标志的数据包到服务端,用以关闭客户端到服务器的数据传送,客户端进入FIN-WAIT-1状态;
- 第二次挥手:服务器收到FIN(SEQ=X)标志的数据包后,发送ACK(ACK=x+1)标志的数据包到客户端,服务端进入CLOSE-WAIT状态,客户端进入FIN-WAIT-2状态;
- 第三次挥手:服务端发送FIN(SEQ=y)标志的数据包到客户端,请求关闭连接,服务端进入LAST-ACK状态;
- 第四次挥手:客户端发送ACK(ACK=y+1)标志的数据包到服务端,客户端进入TIME-WAIT状态,服务端接收到ACK(ACK=y+1)后进入CLOSE状态。客户端若在等待2MSL后仍未接收到回复,则证明服务端已正常关闭,随后客户端也可以关闭连接。
只要四次挥手未结束,客户端和服务端可继续传输数据。
这里总结了一些与TCP三次握手和四次挥手相关的重要面试题:
- 为什么要三次握手?
- 第二次握手时传回ACK,为什么还要传回SYN?
- 为什么要四次挥手?
- 为什么不能将服务器发送的ACK与FIN合并,变为三次挥手?
- 如果第二次挥手时服务器的ACK未送达客户端,会怎样?
- 为什么在第四次挥手时客户端需要等待2*MSL(报文段最长寿命)时间后才进入CLOSED状态?
参考答案:TCP为什么要三次握手和四次挥手?。

了解CopyOnWrite吗?
Copy-On-Write是一种优化策略,核心思想是当多个调用者同时请求相同资源时,他们会共同获取相同的指针,直到某个调用者尝试修改资源内容,系统才会复制一份专用副本。
CopyOnWriteArrayList线程安全的核心在于采用了写时复制策略。当需要修改CopyOnWriteArrayList的内容时,不会直接修改原数组,而是先创建底层数组的副本,进行修改后再赋值回去,从而保证写操作不会影响读操作。
写时复制机制适用于读多写少的并发场景,能够显著提高系统的并发性能。但机制并非完美,还存在一些缺点:
- 内存占用:每次写操作都需复制原始数据,可能导致内存资源不足;
- 写操作开销:每次写操作需复制原始数据,开销较大,频繁写入时性能受影响;
- 数据一致性问题:修改操作不会立即反映到最终结果中,需等待复制完成,可能导致一致性问题。
Redis持久化机制及AOF
Redis的持久化机制是后端面试中非常高频的知识点,需重点掌握。即使不为面试准备,日常开发中也经常用到。
Redis的缓存击穿、穿透、雪崩及解决方案
缓存穿透
缓存穿透是指大量请求的key既不在缓存中,也不存在于数据库中,导致请求直接落到数据库上,可能造成数据库宕机。
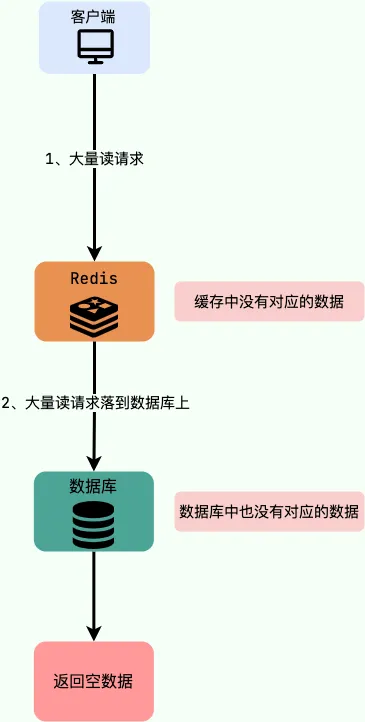
解决方案:
- 进行参数校验,非法请求直接返回错误信息;
- 针对无效key,可在Redis中记录并设置过期时间,避免重复请求。
public Object getObjectInclNullById(Integer id) {
// 从缓存中获取数据
Object cacheValue = cache.get(id);
// 缓存为空
if (cacheValue == null) {
// 从数据库中获取
Object storageValue = storage.get(key);
// 缓存空对象
cache.set(key, storageValue);
// 设置过期时间
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
}
return cacheValue;
}
缓存击穿
缓存击穿是指请求的key对应热点数据,该数据存在于数据库中但不在缓存中(通常因缓存过期),可能导致瞬时大量请求直接打到数据库上。
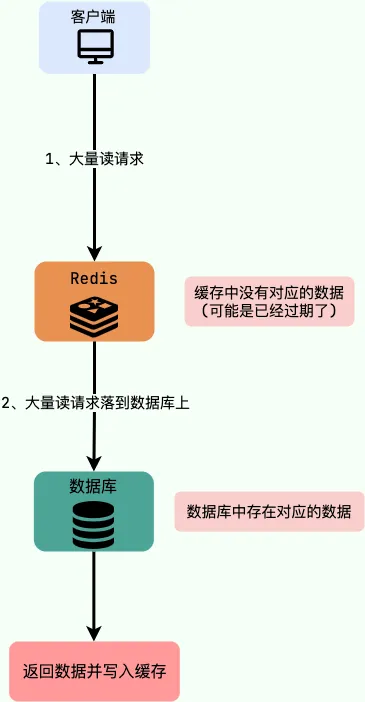
解决方案:
- 热点数据设置较长的过期时间;
- 数据预热,将热点数据提前存入缓存。
缓存雪崩
缓存雪崩描述的是缓存同一时刻大面积失效,导致大量请求直接落到数据库上,造成巨大的压力。
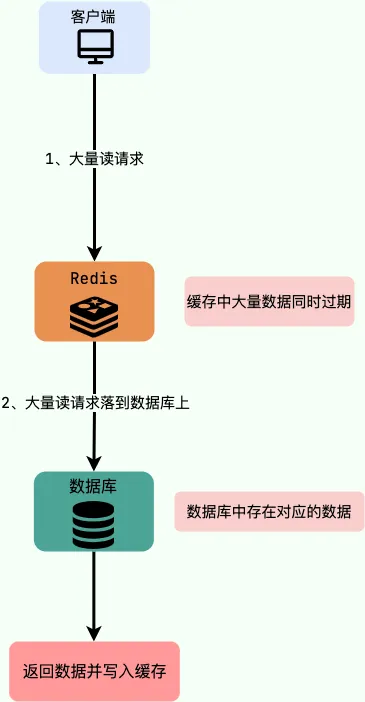
解决方案:
- 针对Redis服务不可用的情况,采用Redis集群;
- 设置不同的失效时间,避免同时失效。
Spring循环依赖及解决办法
循环依赖是指Bean对象循环引用,是两个或多个Bean相互持有对方的引用。
@Component
public class CircularDependencyA {
@Autowired
private CircularDependencyB circB;
}
@Component
public class CircularDependencyB {
@Autowired
private CircularDependencyA circA;
}
SpringBoot 2.6.x以前默认允许循环依赖,利用三级缓存机制解决,但在2.6.x之后官方不再推荐编写存在循环依赖的代码。
解决方法:
- 在全局配置文件中设置允许循环依赖:
spring.main.allow-circular-references=true; - 在导致循环依赖的Bean上添加
@Lazy注解。
MySQL日志及其作用
MySQL中常见的日志类型主要有:
- 错误日志:记录MySQL的启动、运行、关闭过程;
- 二进制日志:记录更改数据库数据的SQL语句;
- 一般查询日志:记录所有SQL请求,不建议开启;
- 慢查询日志:记录超时的查询;
- 事务日志:包括redo log和undo log;
- 中继日志:用于主从复制;
- DDL日志:记录DDL语句的元数据操作。
**二进制日志(binlog)**主要记录数据库执行的更改操作,包括DDL和DML语句。binlog的主要应用场景是主从复制。
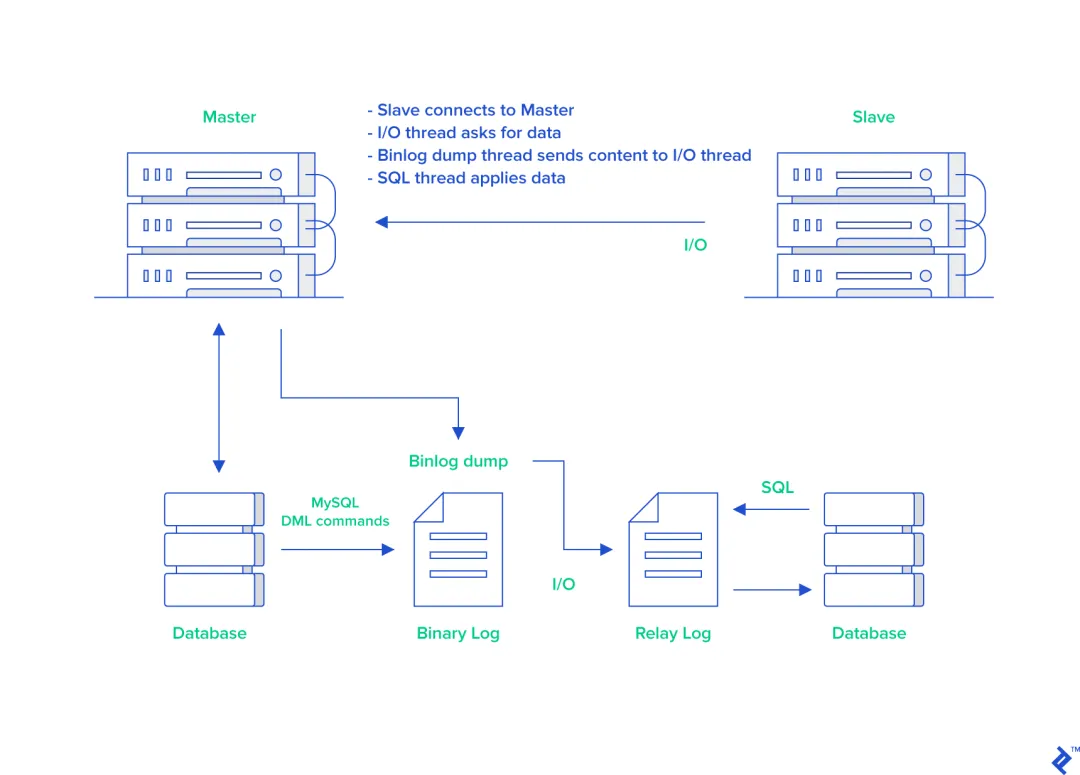
主从复制的过程是:
- 主库将数据变化写入binlog;
- 从库连接主库,创建I/O线程请求更新的binlog;
- 主库创建binlog dump线程发送binlog;
- 从库的I/O线程接收binlog并写入到relay log;
- 从库的SQL线程读取relay log同步数据。
关于MySQL binlog的详细介绍,建议查看这篇文章:MySQL binlog有何作用?主从延迟的了解吗?。
字符串字符出现次数统计
以下是利用TreeMap统计字符串中每个字符出现次数并按字母表顺序输出的代码示例:
public static String countCharacters(String str) {
Map<Character, Integer> countMap = new TreeMap<>();
for (char c : str.toCharArray()) {
countMap.put(c, countMap.getOrDefault(c, 0) + 1);
}
StringBuilder sb = new StringBuilder();
for (Map.Entry<Character, Integer> entry : countMap.entrySet()) {
sb.append(entry.getKey()).append(entry.getValue());
}
return sb.toString();
}
测试代码:
String str = "ababccdccddddf";
String result = countCharacters(str);
System.out.println(result);
输出:
a2b2c4d5f1
这篇文章的内容全面覆盖了招银网络面试常见问题及解决方案,希望能帮助到正在准备面试的你们。