
一、引言
在人工智能的发展浪潮中,大型语言模型(LLMs)已成为自然语言处理(NLP)研究和应用的核心。Qwen2-7B模型作为行业的佼佼者,由于其巨大的参数量和卓越的功能,备受瞩目。尤其是在微调后,模型能够更好地执行特定任务。本文将详细介绍如何利用LLaMA-Factory框架高效地微调Qwen2-7B模型,以提升其在特定任务中的表现。
二、LLaMA-Factory框架概述
LLaMA-Factory是一个集成多种微调技术的高效框架,支持多种大型语言模型,包括Qwen2-7B。它结合了先进的微调算法,如LoRA和QLoRA,并提供实验监控工具,例如LlamaBoard和TensorBoard,从而为用户创造了一个便捷有效的微调环境。此外,LLaMA-Factory还支持多模态训练和多种硬件平台,包括GPU和Ascend NPU,进一步扩展了其应用范围。

三、ModelScope的安装
由于国内网络环境的特殊性,从国际知名模型库如Hugging Face直接下载模型可能会遭遇速度慢或连接不稳等问题。为了解决这个问题,我们选择使用国内的ModelScope平台进行模型下载。ModelScope不仅提供丰富的模型资源,还针对国内用户进行了下载速度优化。
修改模型库为ModelScope:
export USE_MODELSCOPE_HUB=1
export MODELSCOPE_CACHE=/root/autodl-tmp/models/modelscope
学术资源加速:
source /etc/network_turbo
安装ModelScope(用于下载相关模型):
pip install modelscope
四、模型下载步骤
在下载Qwen2-7B模型之前,需设置ModelScope的环境变量,确保模型能够正确缓存到指定路径,以避免由于默认路径导致的空间不足问题。接下来,通过编写简单的Python脚本,利用ModelScope的API进行模型下载。
使用ModelScope中的snapshot_download函数进行模型下载,模型名称为第一个参数,cache_dir为模型下载路径。
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen2-7B', cache_dir='/root/autodl-tmp', revision='master')
运行脚本python /root/autodl-tmp/d.py以执行下载,完成后如下所示:
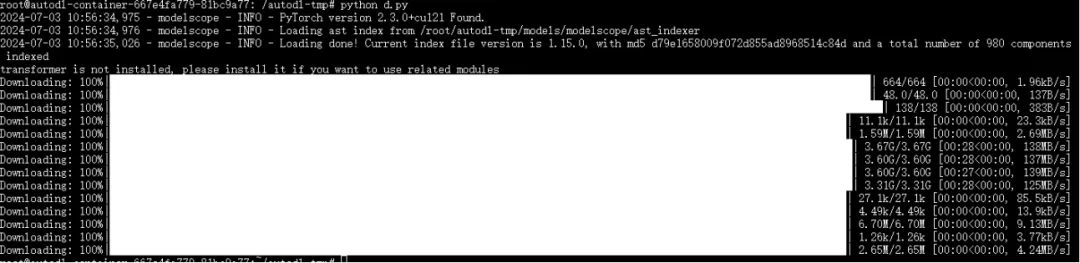
五、LLaMA-Factory的安装
LLaMA-Factory的安装过程相对简单,只需通过Git克隆仓库,并使用pip进行安装。这一过程是微调流程的基础,为后续操作提供了必要的工具和库。
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
六、启动LLaMA-Factory
安装完成后,可以通过简单的命令启动LLaMA-Factory的Web UI界面。该界面提供直观友好的操作环境,使微调过程更加便捷。
修改Gradio默认端口:
export GRADIO_SERVER_PORT=6006
启动LLaMA-Factory:
llamafactory-cli webui
启动后的界面如下所示:

七、LLaMA-Factory操作实践
1. 访问UI界面
通过访问http://localhost:6006/,用户可以进行模型配置、训练参数设置以及微调过程监控。
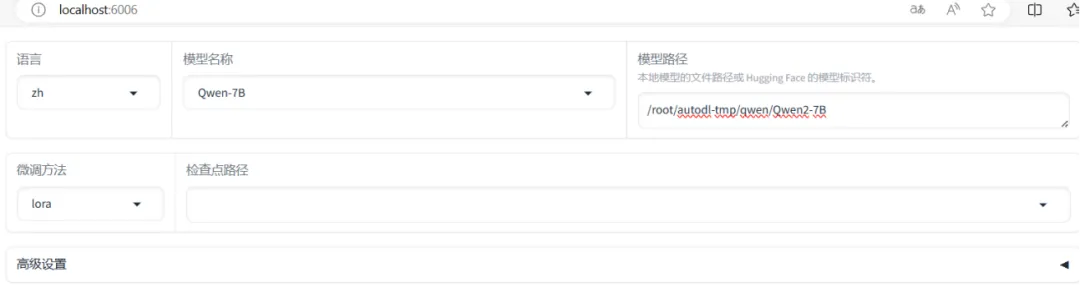
2. 配置模型本地路径
在UI界面中,用户可以根据需要选择模型来源,既可以直接使用Hugging Face模型库的资源,也可以加载本地下载的模型。
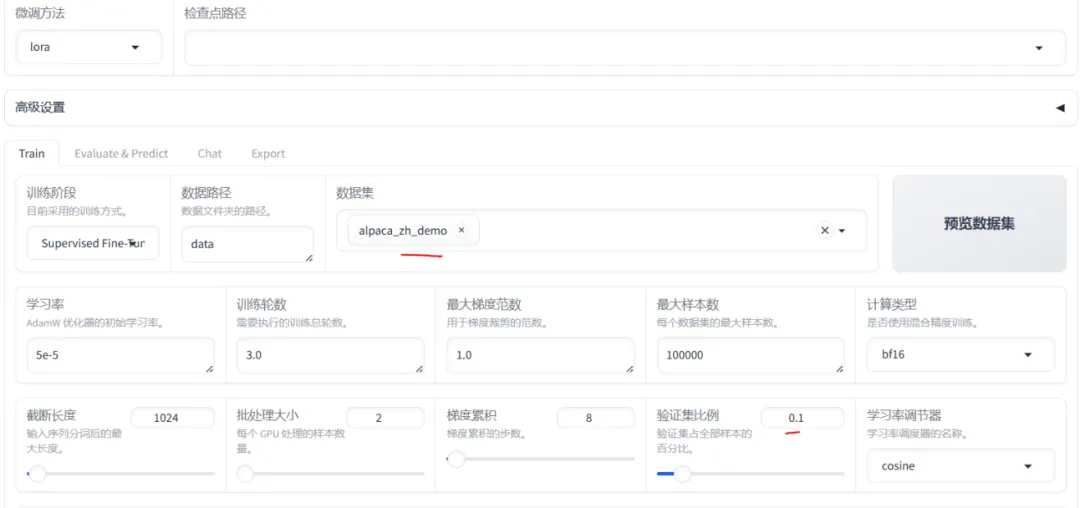
3. 微调配置
微调配置是整个流程中至关重要的一步。用户需要根据具体任务需求设置训练阶段、数据集、学习率、批次大小等关键参数。
4. 预览训练参数
在开始训练之前,用户可以预览所有训练参数,以确保配置无误。点击“预览命令”按钮查看训练参数配置,并可进行手动修改。
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /root/autodl-tmp/qwen/Qwen2-7B \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--quantization_method bitsandbytes \
--template default \
--flash_attn auto \
--dataset_dir data \
--dataset alpaca_zh_demo \
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir saves/Qwen-7B/lora/train_2024-07-03-11-30-41 \
--bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all \
--val_size 0.1 \
--eval_strategy steps \
--eval_steps 100 \
--per_device_eval_batch_size 2
5. 开始训练
确认配置无误后,用户可以启动训练过程。LLaMA-Factory将根据用户的配置进行模型微调。点击“开始”按钮以启动训练。
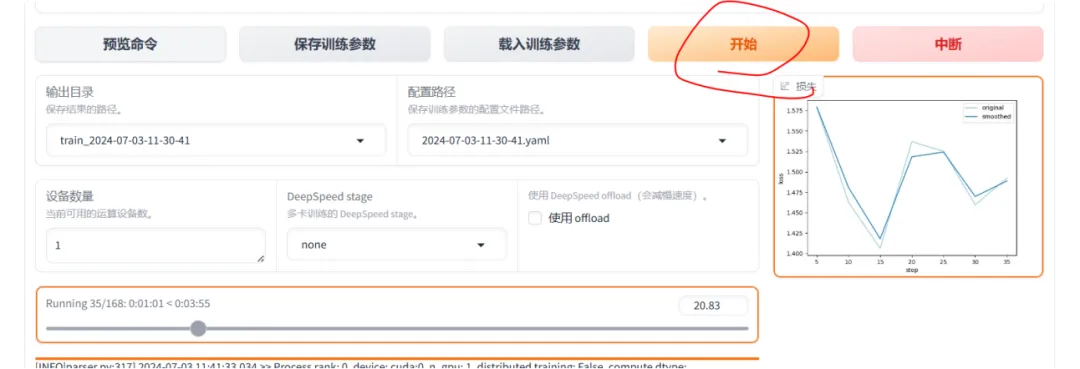
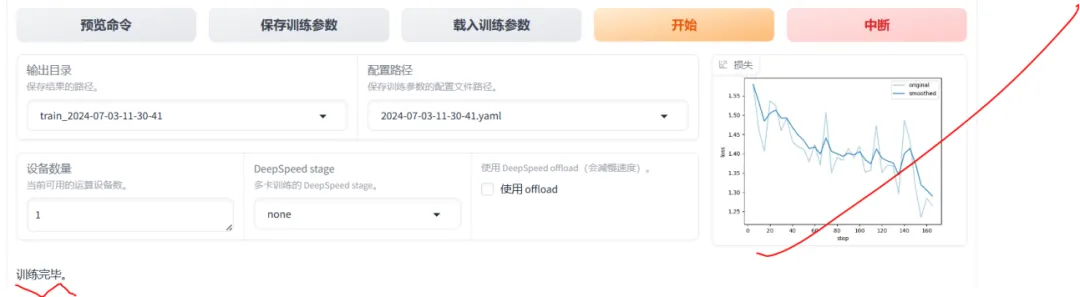
训练完成后的结果如下:
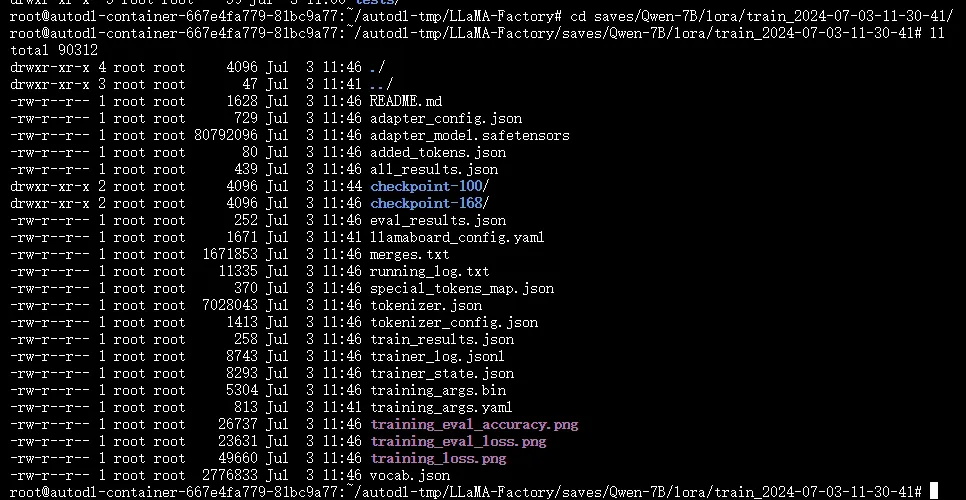
完成训练后,系统会在本地输出微调后的权重文件,Lora权重文件输出如下:
八、模型加载与推理
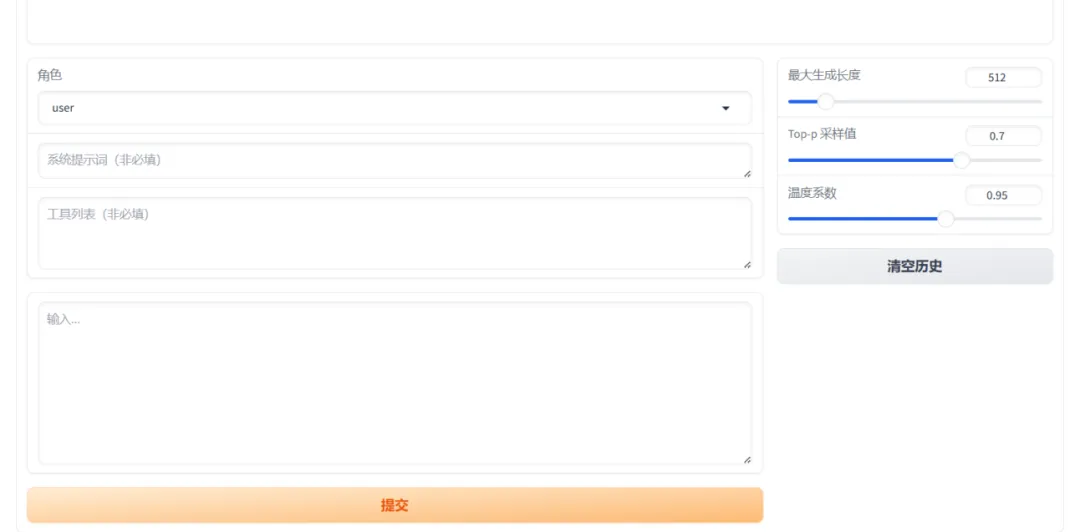
在高级设置中,有一个“Chat”标签可用于模型推理对话。
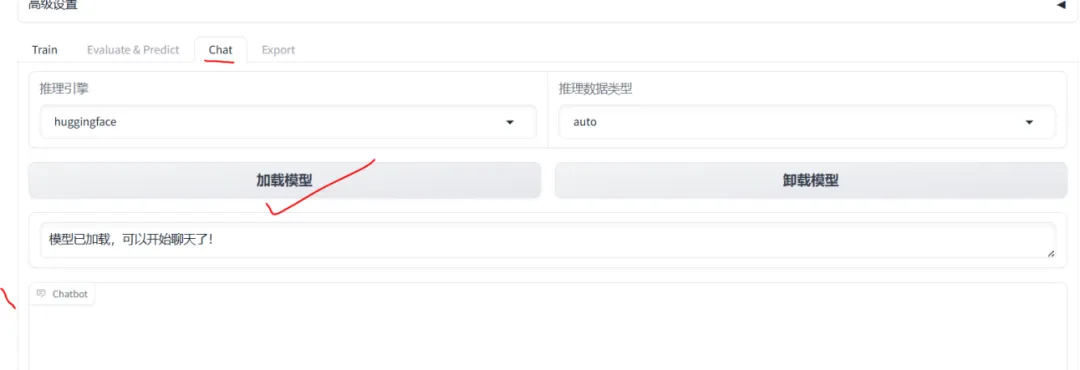
模型对话示例:
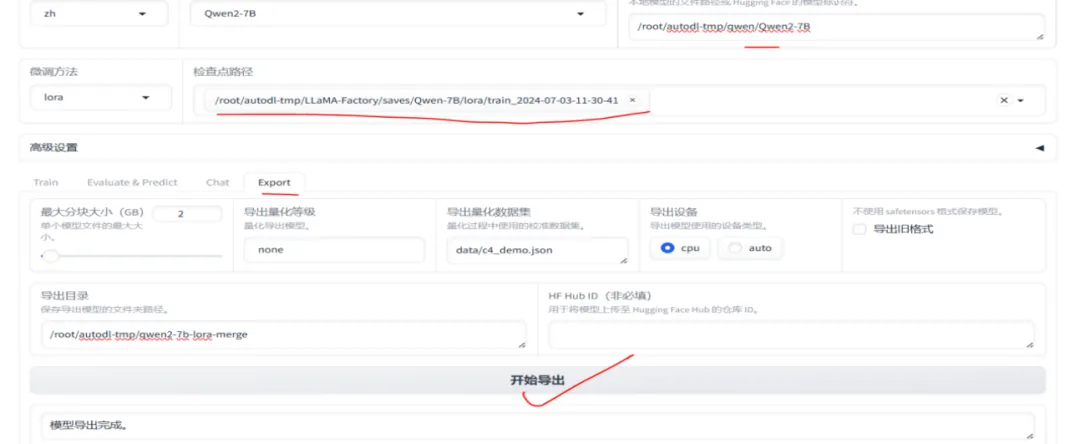
7. 模型合并与导出
在模型训练完成后,可以将训练生成的Lora相关权重文件与基础模型进行合并导出,生成新的模型。
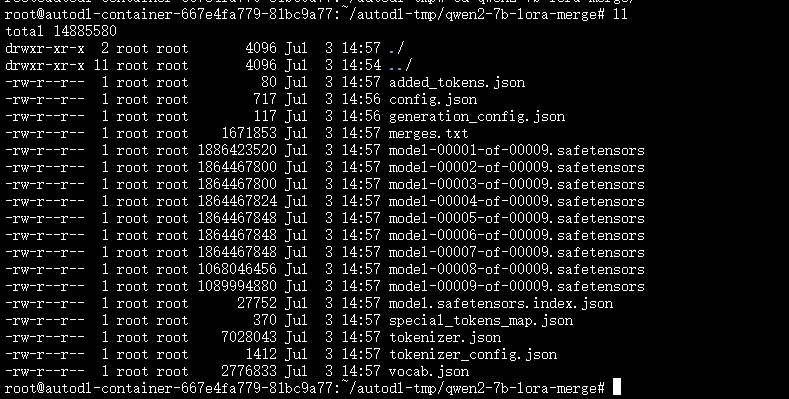
合并后的模型文件如下:
导出后,用户可以基于新模型进行推理对话。
九、结语
通过本文的详细介绍,读者应对如何使用LLaMA-Factory对Qwen2-7B进行微调有了清晰的理解。微调不仅能提升模型在特定任务上的表现,还可为模型提供更丰富的应用场景。希望本文能为大家的微调实践提供有价值的参考和指导。随着技术的不断进步,期待LLaMA-Factory和Qwen2-7B在未来的AI领域中发挥更大作用。