
MaxKB(Max Knowledge Base)介绍
MaxKB是一款基于大语言模型和RAG(检索增强生成)的开源知识库问答系统,广泛应用于智能客服、企业内部知识库、学术研究和教育等领域。该系统旨在提供高效的知识管理和问答服务。
产品优势
-
开箱即用
用户可以直接上传文档或自动爬取在线文档,系统支持文本自动拆分、向量化处理和RAG技术,有效降低大模型的幻觉现象,提供良好的智能问答交互体验。 -
快速接入
MaxKB支持零编码嵌入到第三方业务系统,快速接入企业微信、钉钉、飞书、公众号等应用,帮助现有系统迅速获得智能问答功能,提升用户满意度。 -
灵活编排
系统内置强大的工作流引擎和函数库,能够灵活编排AI工作过程,以满足复杂业务场景的需求。 -
模型中立
MaxKB支持对接多种大模型,包括本地私有模型(如Llama 3、Qwen 2等)、国内公共模型(如DeepSeek、SILICONFLOW、通义千问等)以及国外公共模型(如OpenAI、Azure OpenAI等)。
安装指南
Docker Compose
以下是配置MaxKB的Docker Compose示例:
services:
maxkb:
image: 1panel/maxkb:latest
container_name: maxkb
volumes:
- /vol1/1000/docker/maxkb/data:/var/lib/postgresql/data
- /vol1/1000/docker/maxkb/python-packages:/opt/maxkb/app/sandbox/python-packages
ports:
- "8080:8080"
restart: always
使用说明
在浏览器中输入 http://NAS的IP:8080,即可访问系统界面。

输入管理员账号和密码进行登录:
- 管理员账号:admin
- 密码:MaxKB@123..

首次使用时,需要修改初始密码。
进入系统面板,界面设计简洁明了。
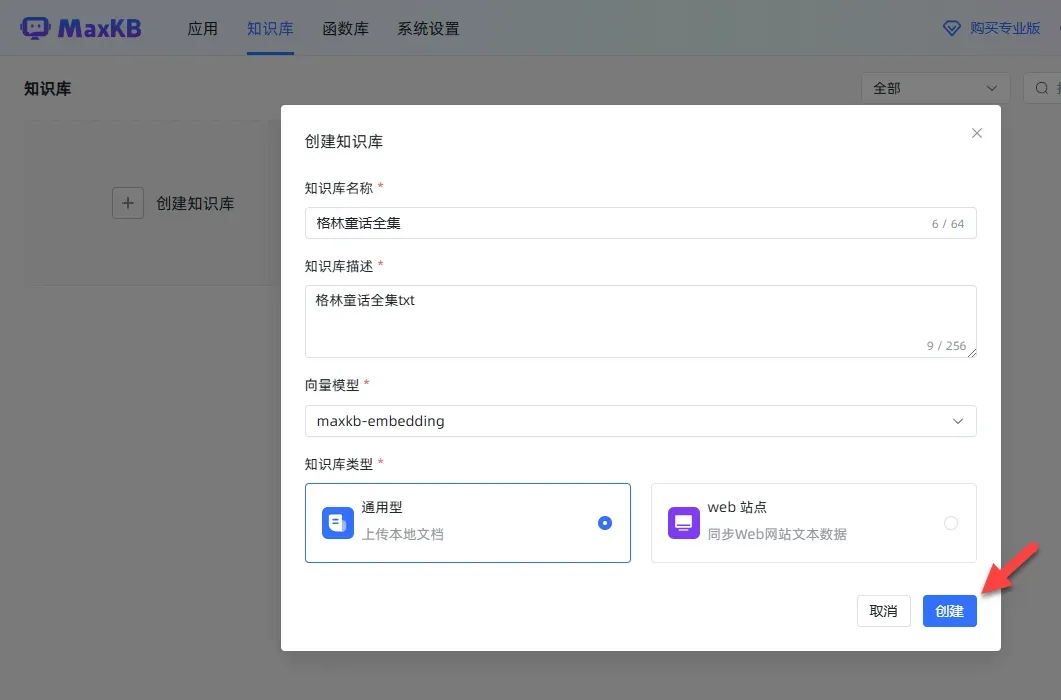
创建知识库
首先创建一个新的知识库。

根据系统提示填写相关信息。
创建完成后,需上传文档以丰富知识库。
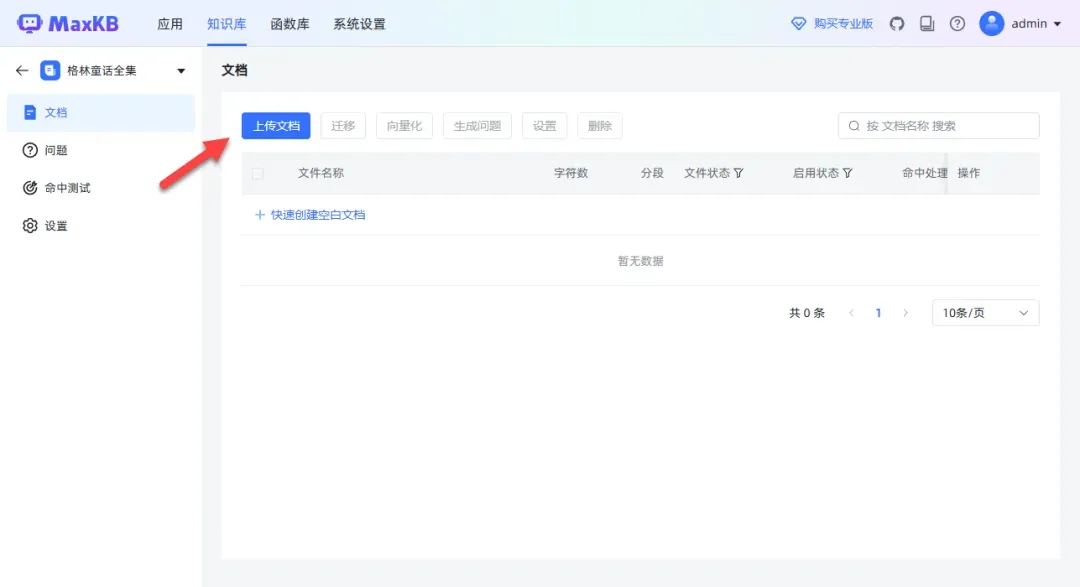
支持上传的文档格式包括TXT、Markdown、PDF、HTML、XLS、XLSX、CSV和ZIP等。
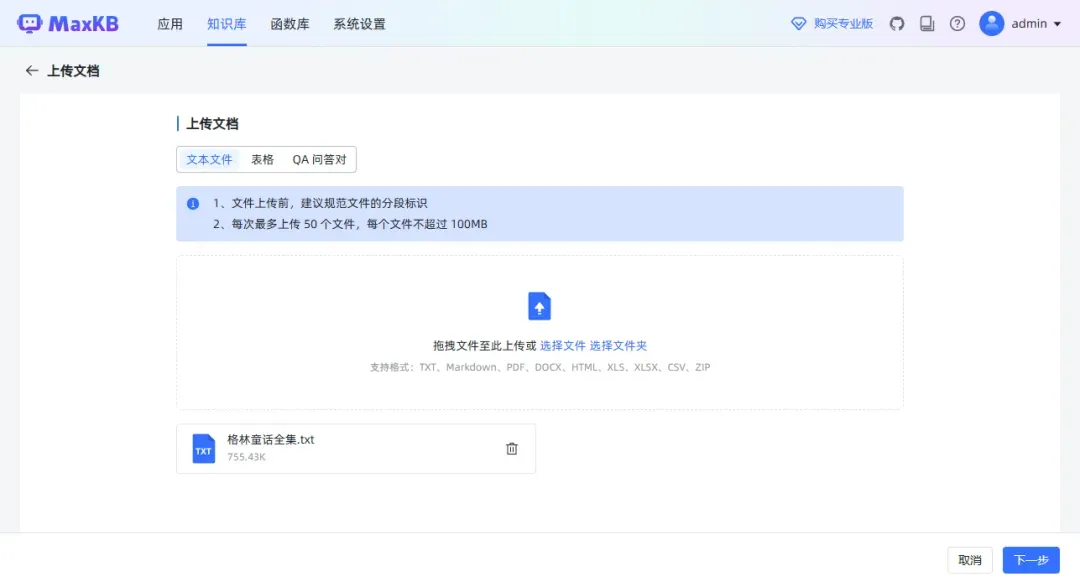
系统会自动进行文本分段,虽然效果可能不够理想(使用VSCode查看文档能更好地展示分段)。
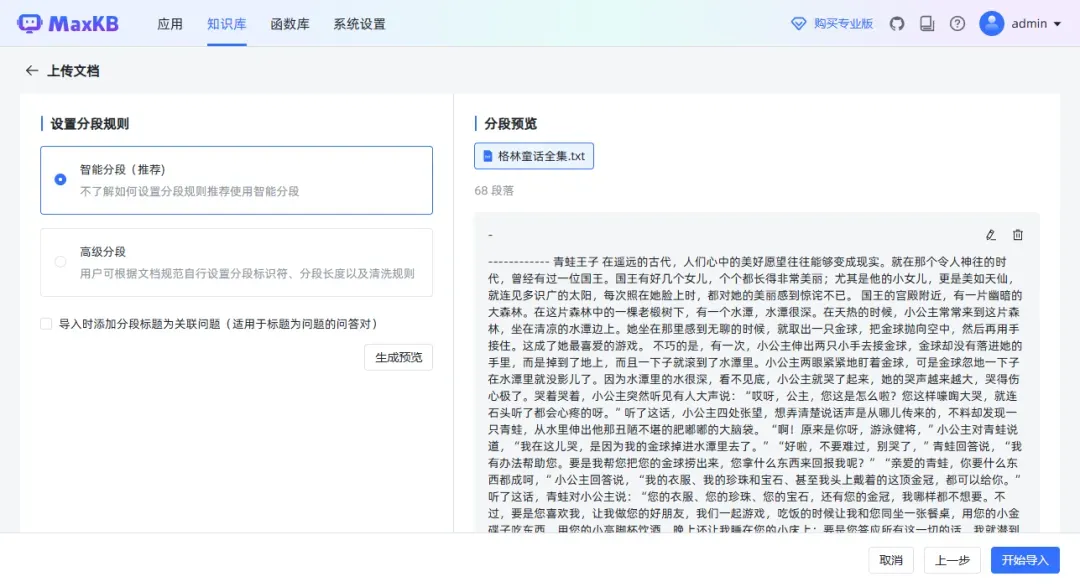
通过选择高级分段选项,可以根据文本中的特殊符号“------------”进行更精确的分段处理。
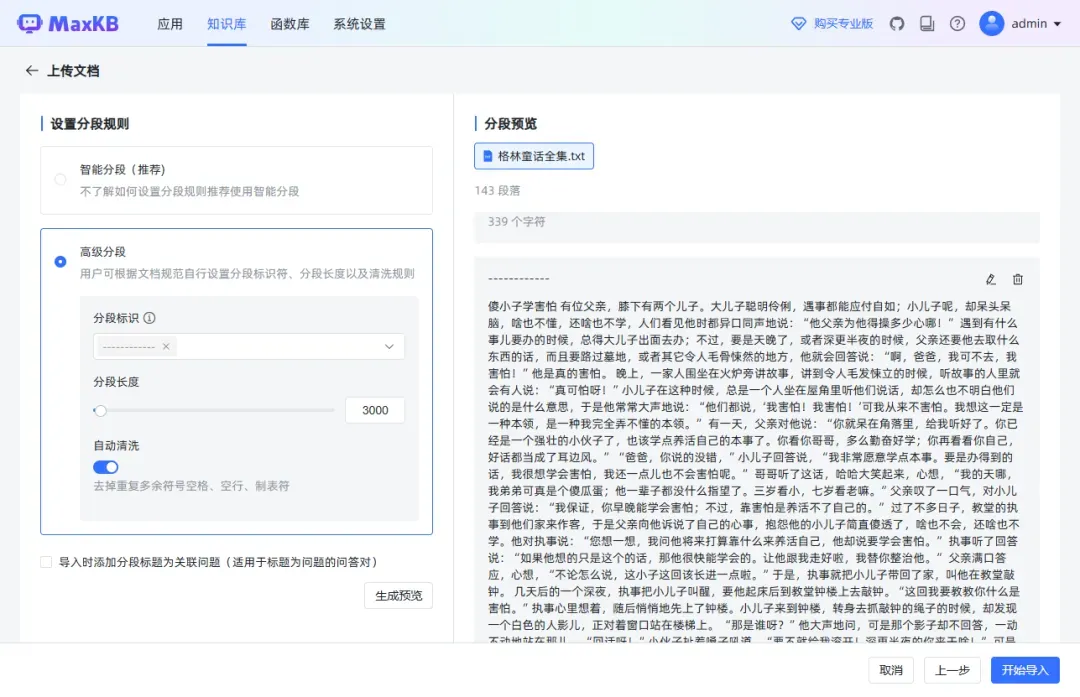
在右侧可以进行文本编辑。
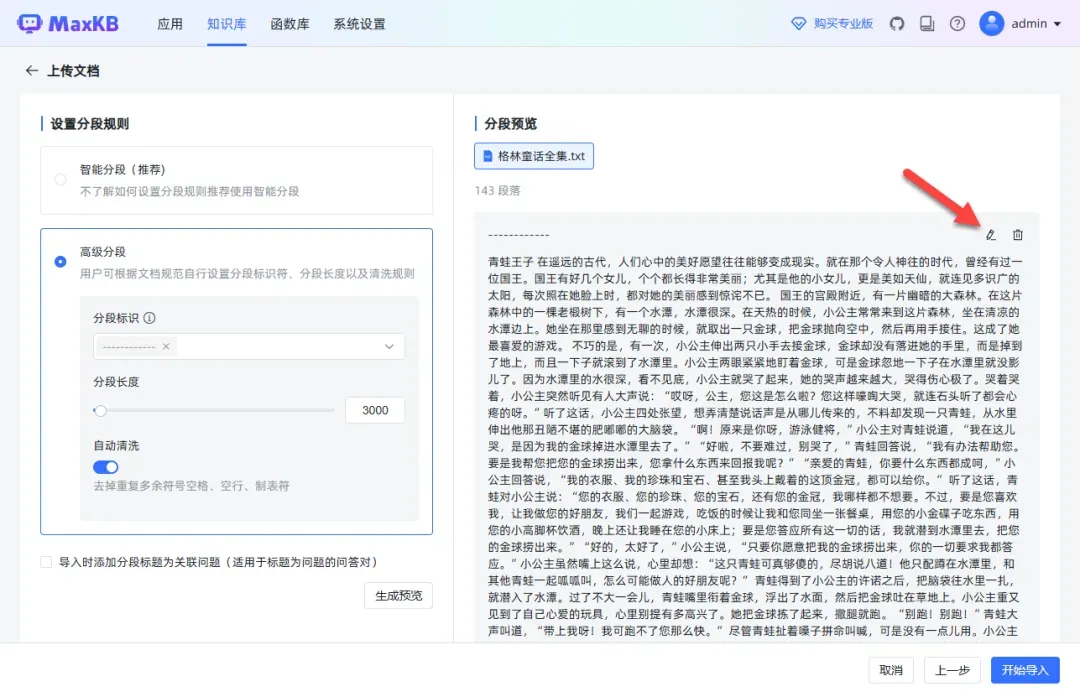
可以为每个分段单独设置标题。
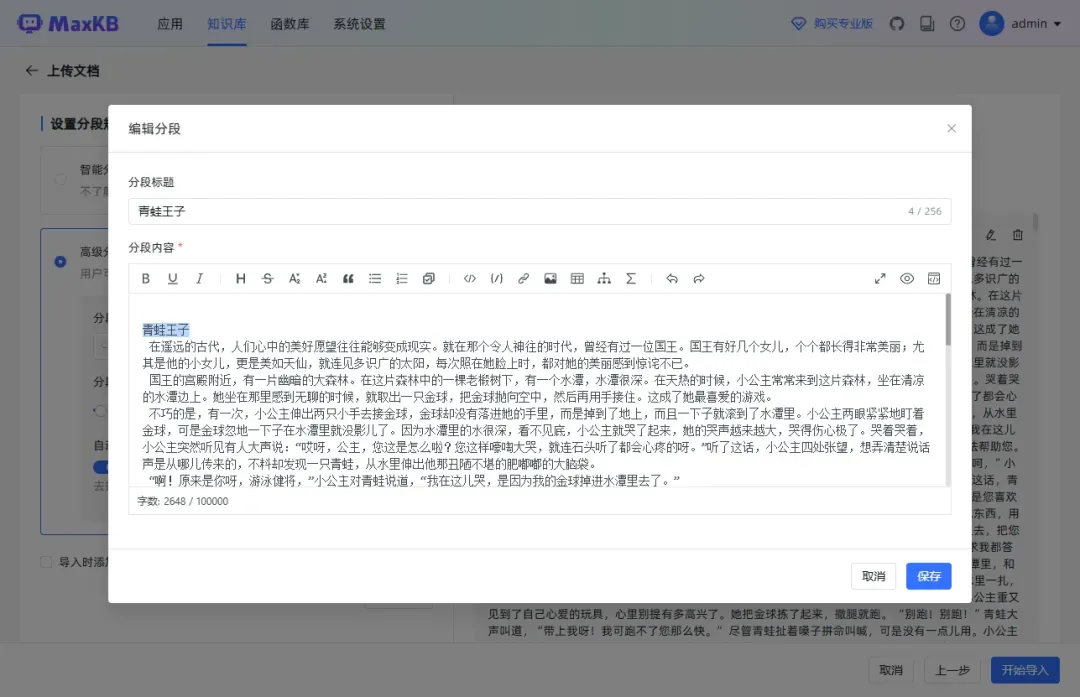
设置完成后,点击“开始导入”。
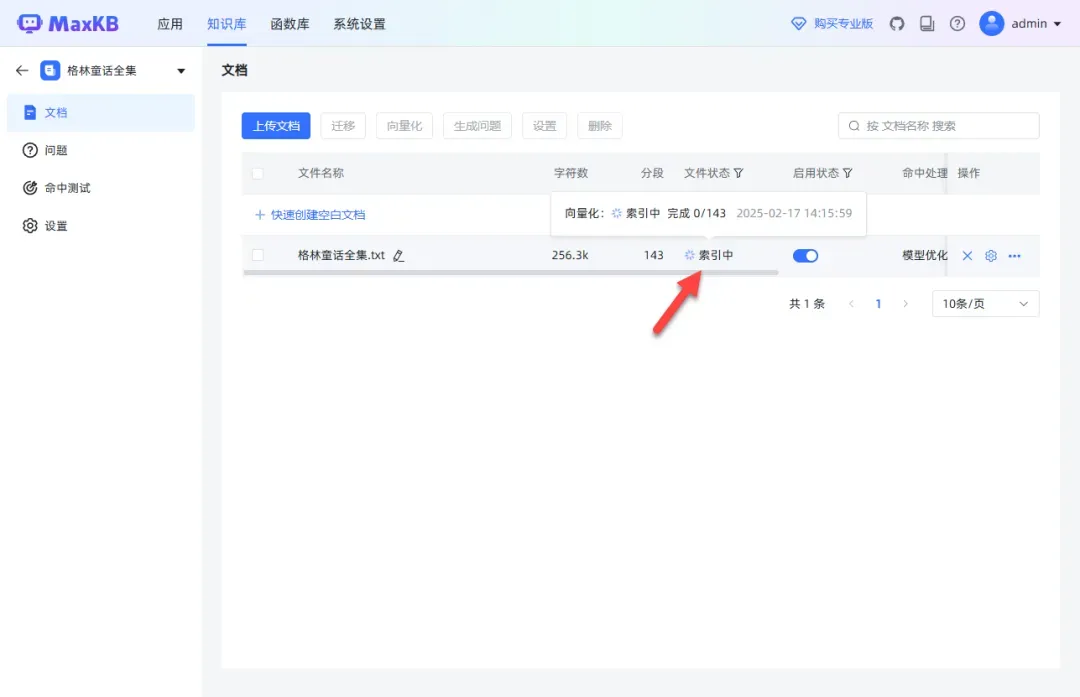
在等待索引完成的同时,还可以继续添加更多文档,丰富知识库内容。
在知识库中,可以创建问题并填写回答内容。
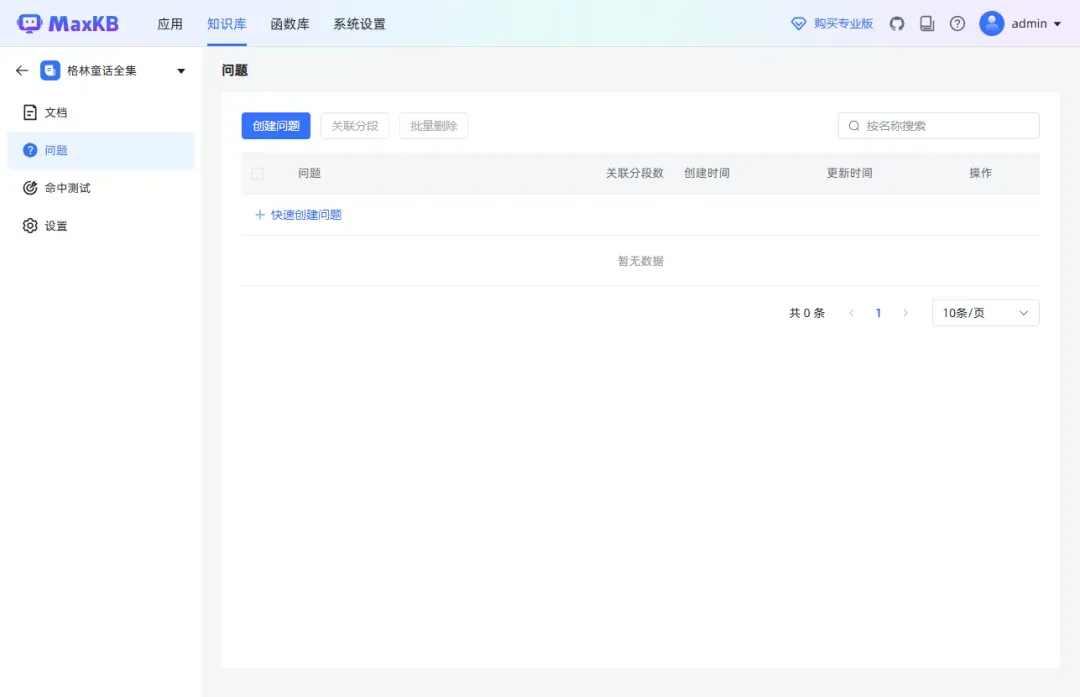
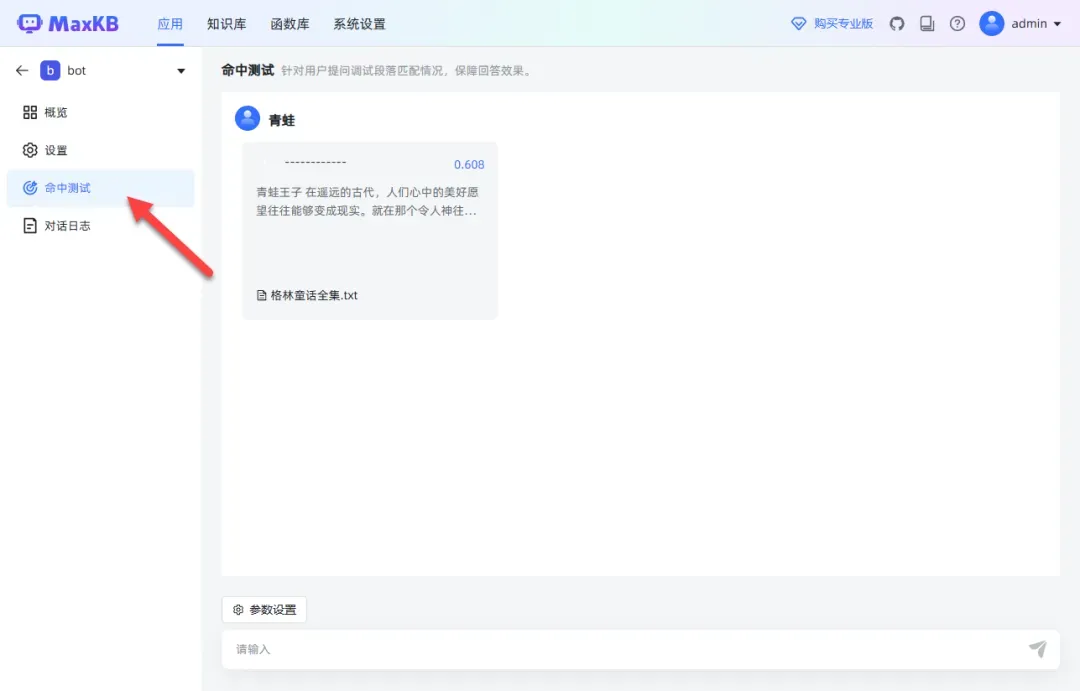
通过输入内容进行命中测试,以验证系统的准确性。
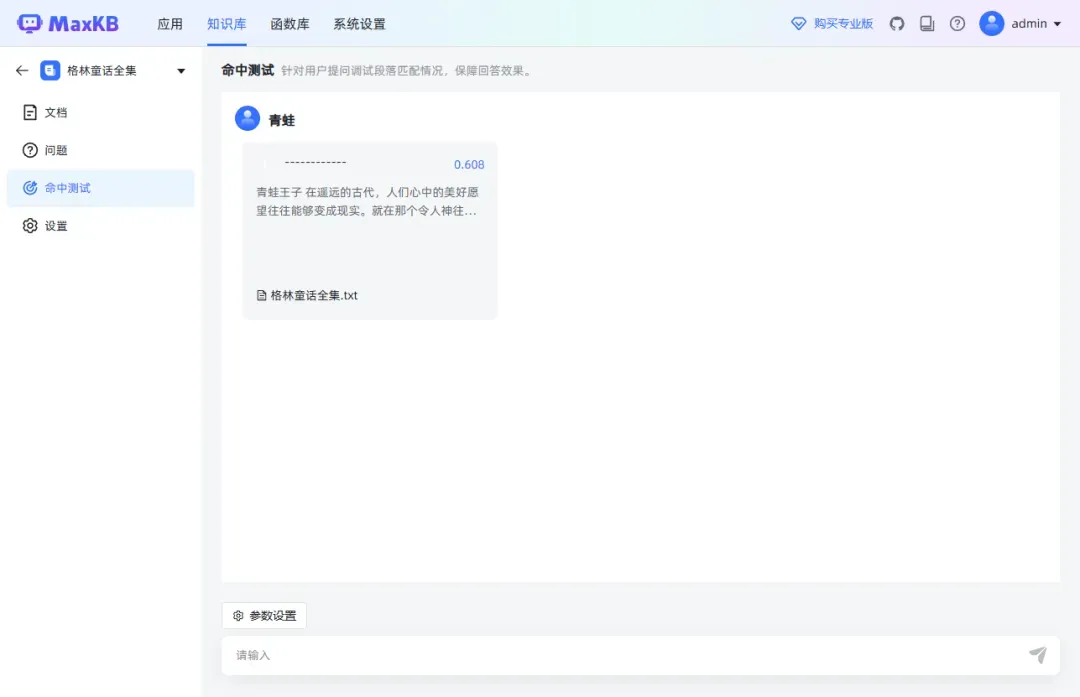
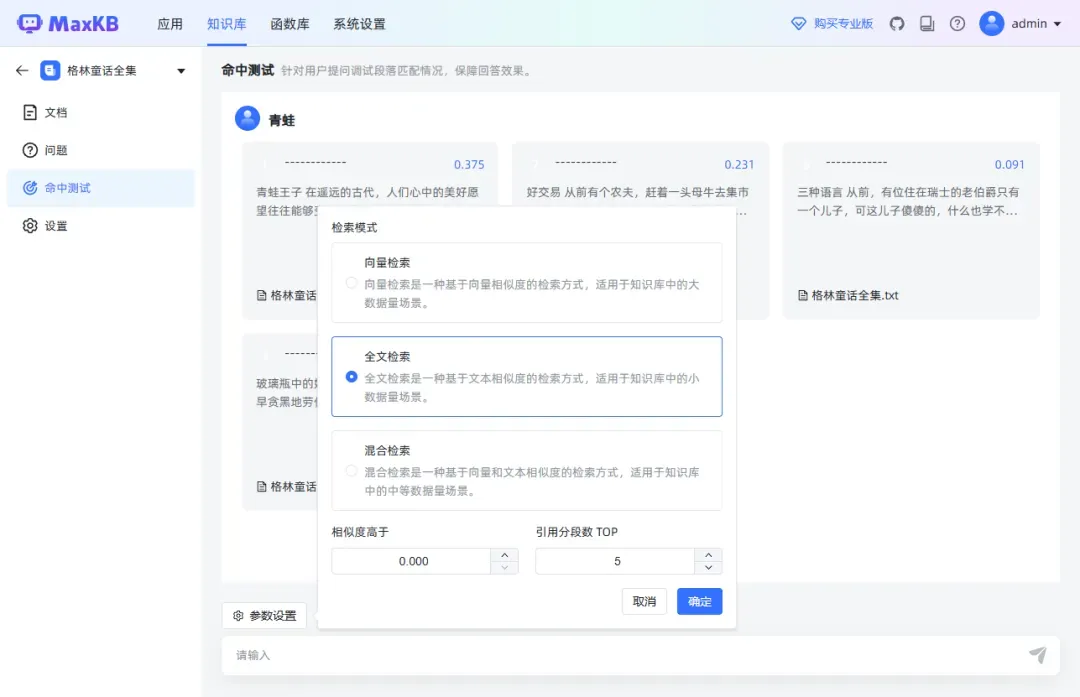
如果命中率较低,可以选择不同的检索模式并调整相关参数设置。
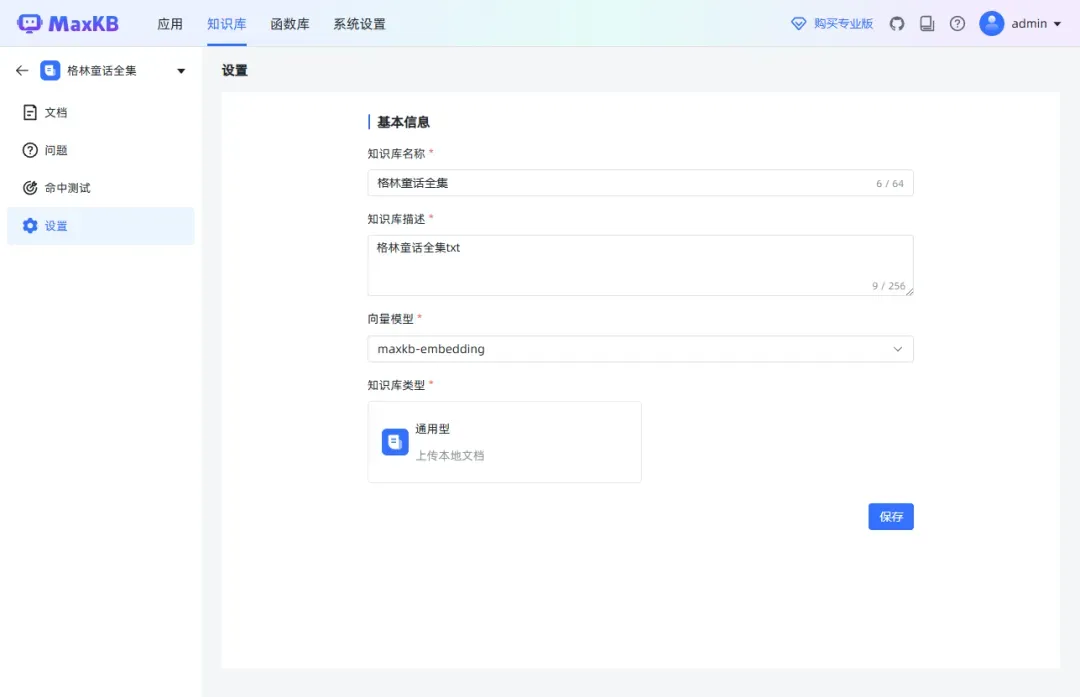
在设置中,可以修改基本信息和关联应用。
添加模型
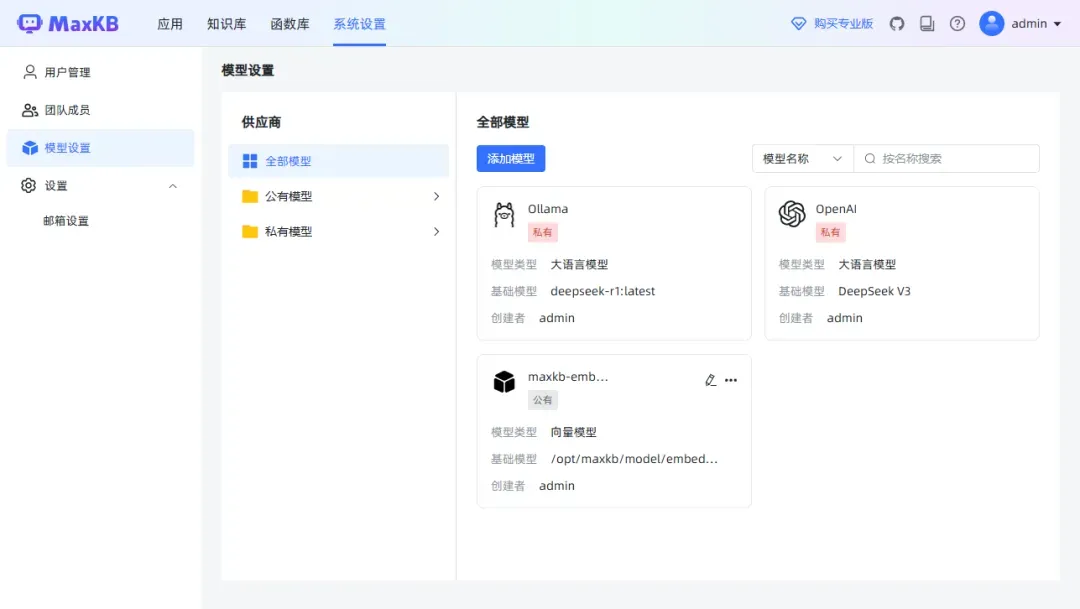
在系统设置中选择模型设置,这里分为公有模型和私有模型。
公有模型支持的平台种类丰富。
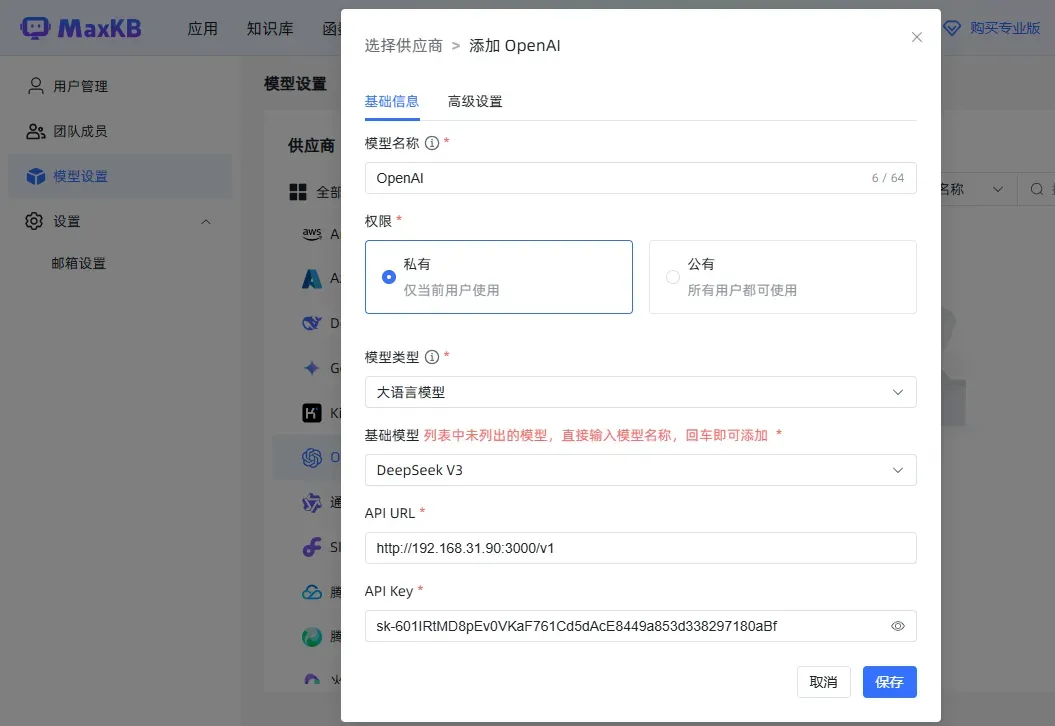
示范添加一个OpenAI模型(通过之前部署的One API)。
以下是参考设置。
私有模型是指在本地运行的模型。
示范添加一个Ollama模型(需在本地运行,速度可能较慢)。
参考设置(API Key可以随意填写)。
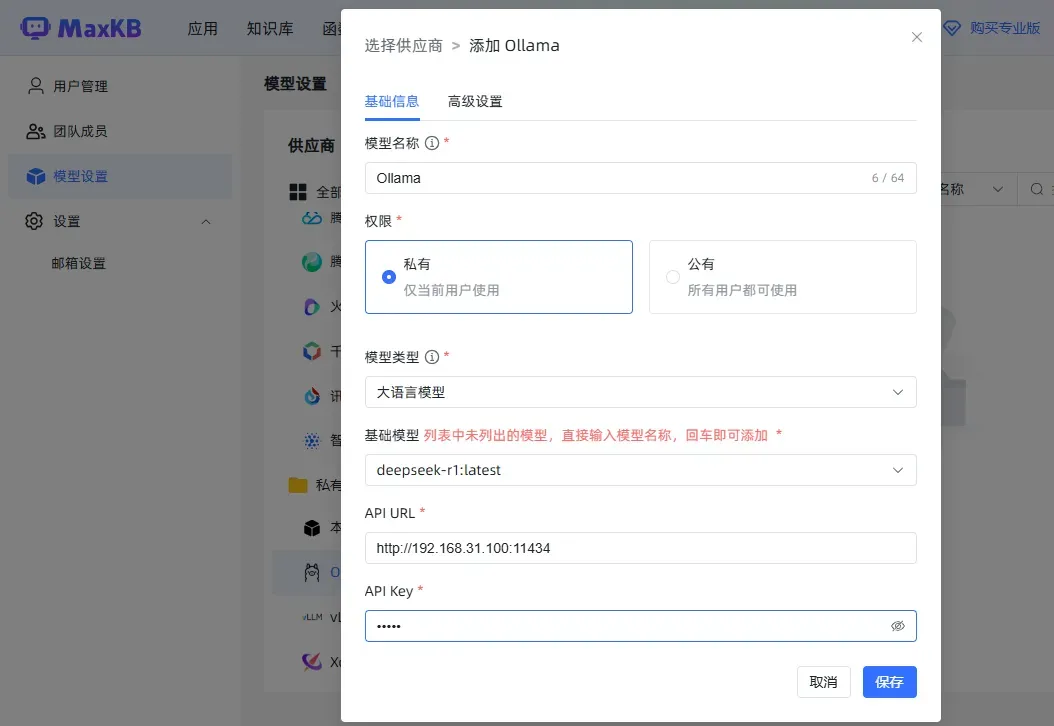
添加模型后即可完成设置。
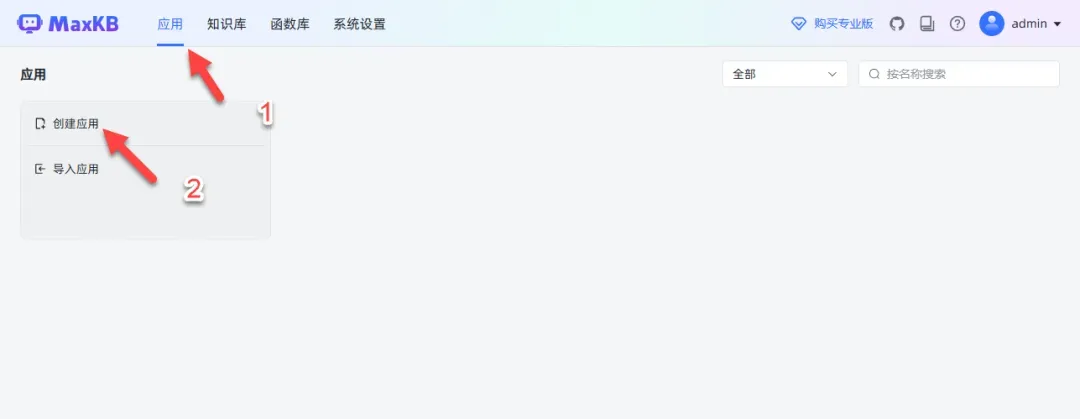
创建应用
在“应用”菜单中选择“创建应用”。
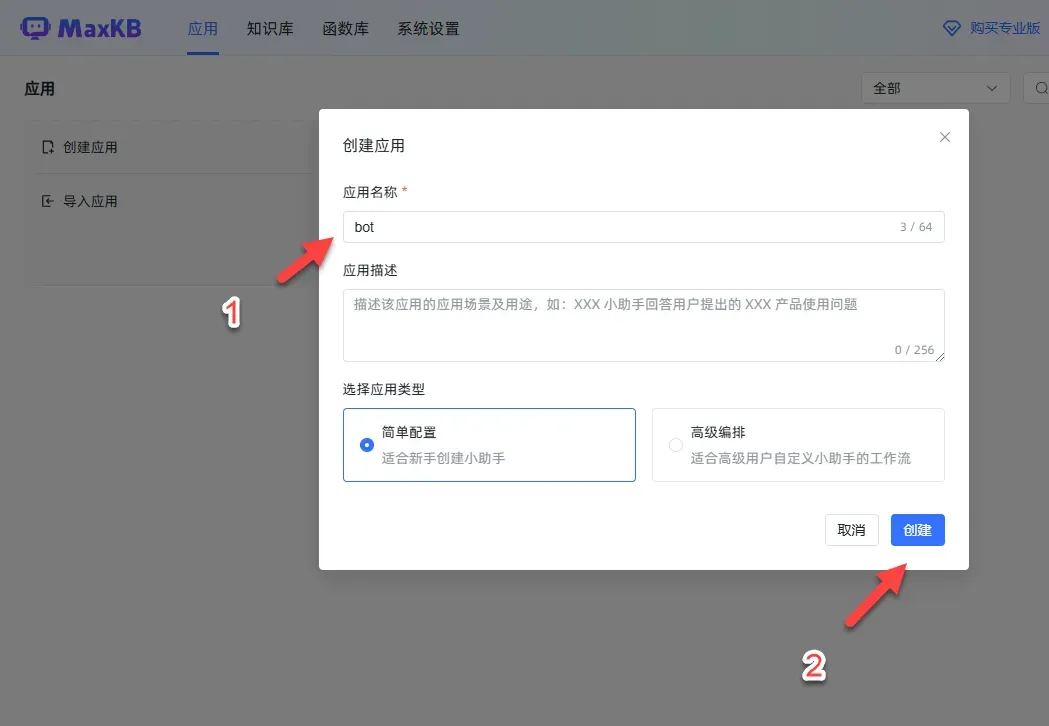
填写应用名称后,点击“创建”即可。
选择AI模型(其他设置可在后续调整)。
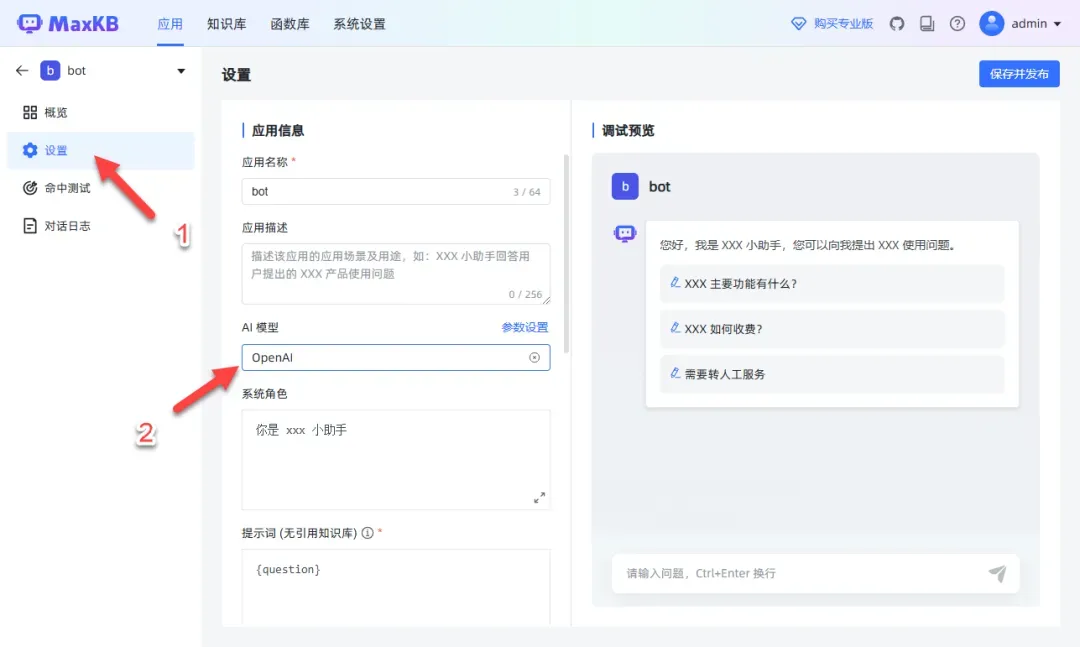
在右侧进行测试,以确保模型可以正常调用。
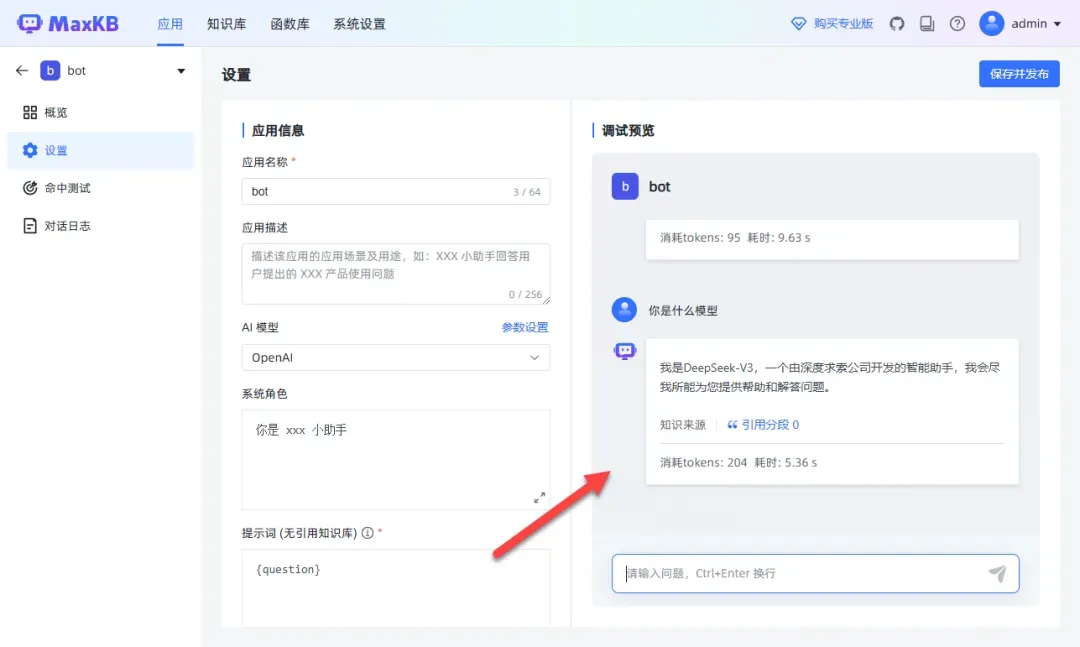
在未关联知识库之前,提问相关内容。
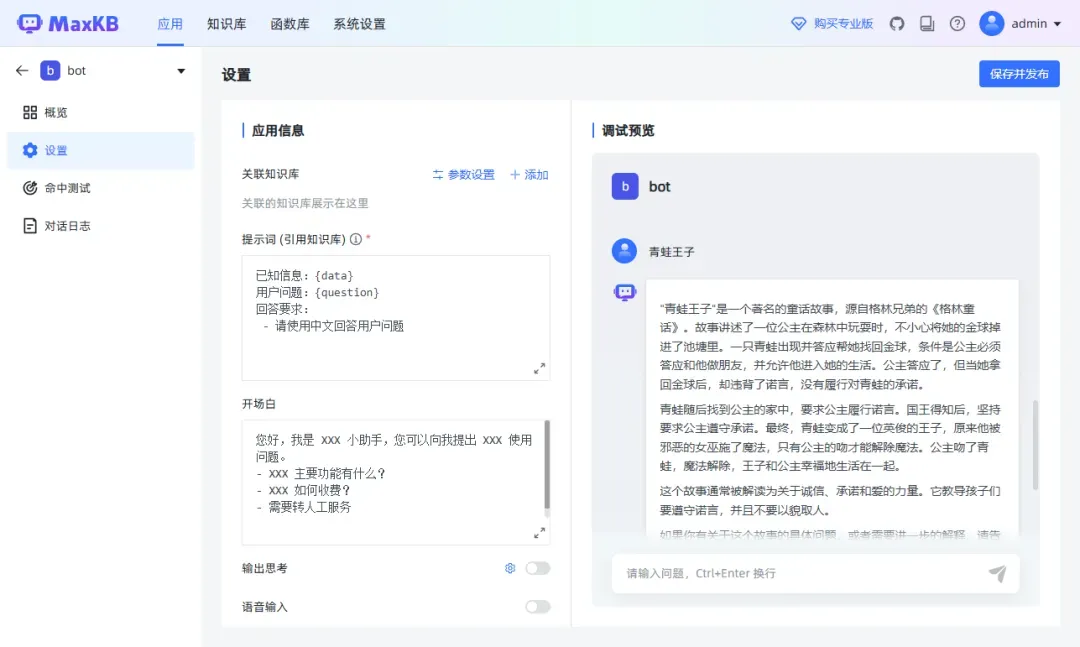
关联知识库后,回复内容会有所不同,效果明显。
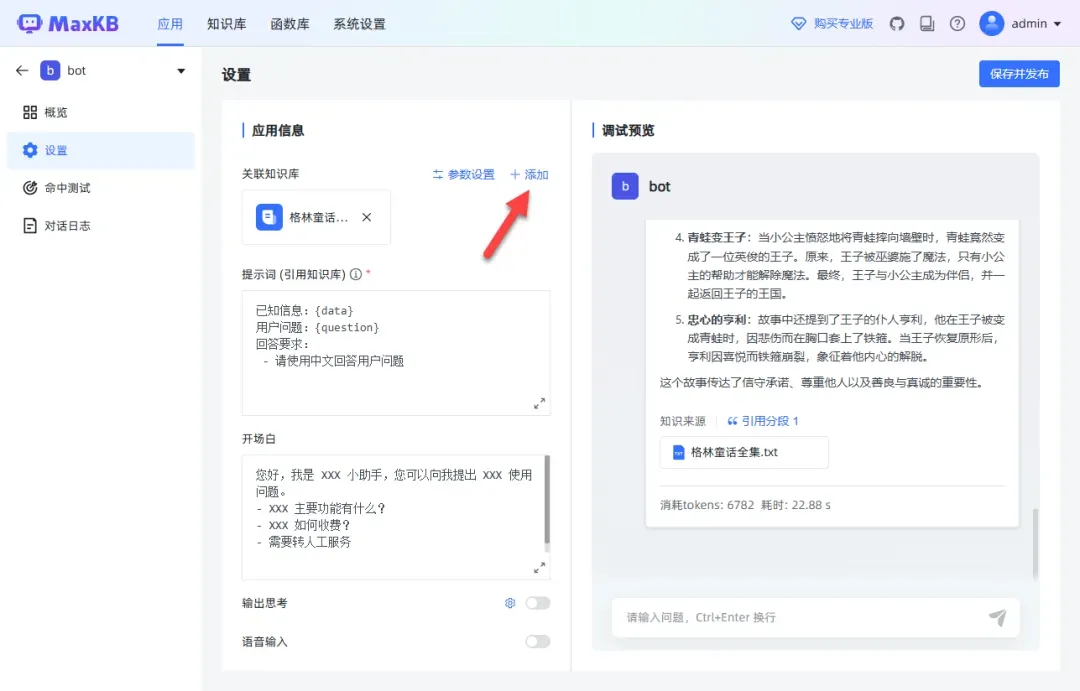
小提示
我测试了使用Ollama本地模型,虽然可行,但速度较慢。
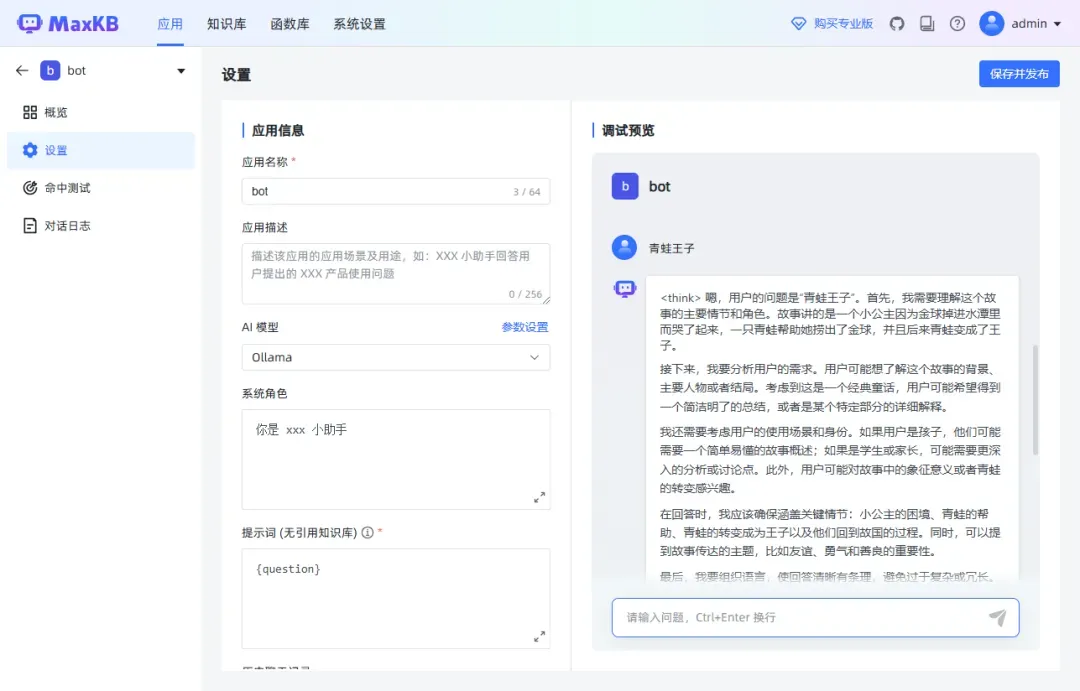
确认无误后,点击“保存并发布”。
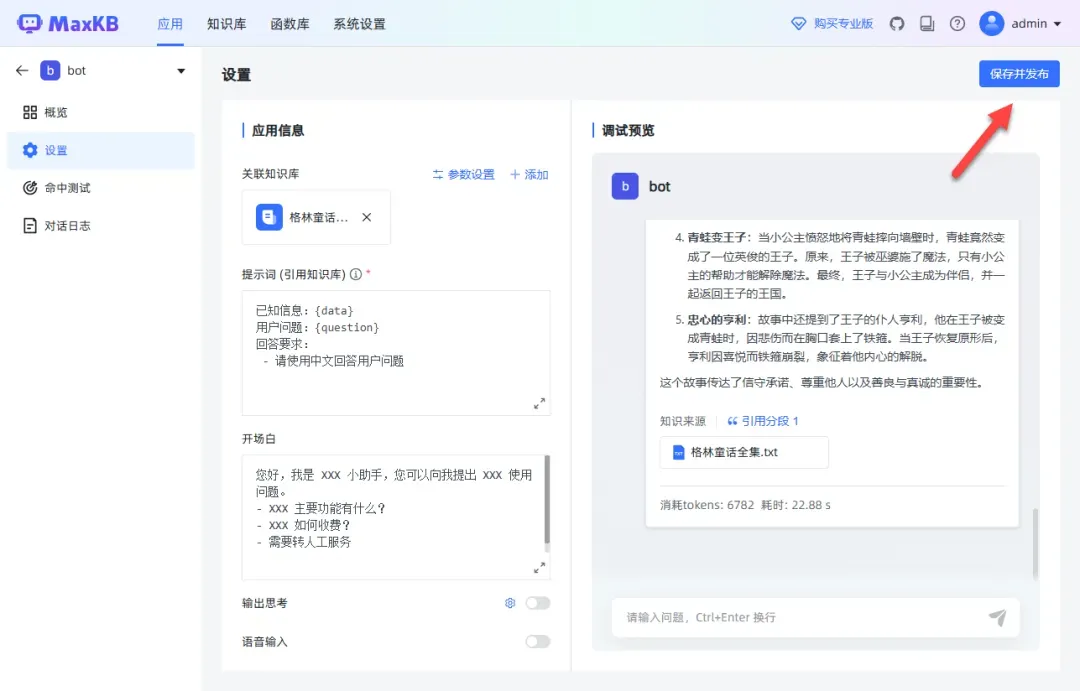
创建完成后,可以点击打开并查看知识库。
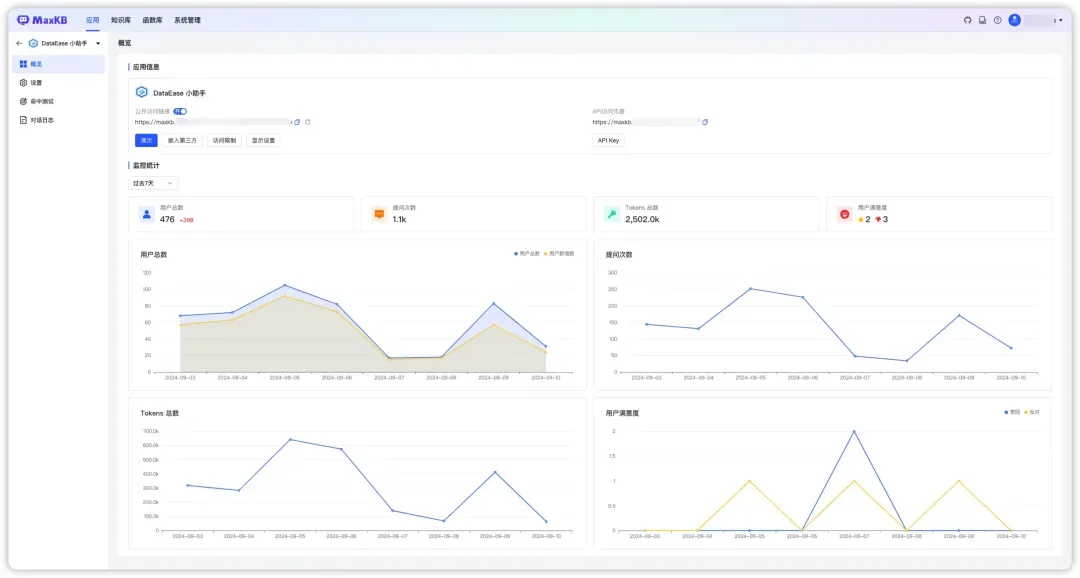
在概览中,数据和图表展示清晰直观。
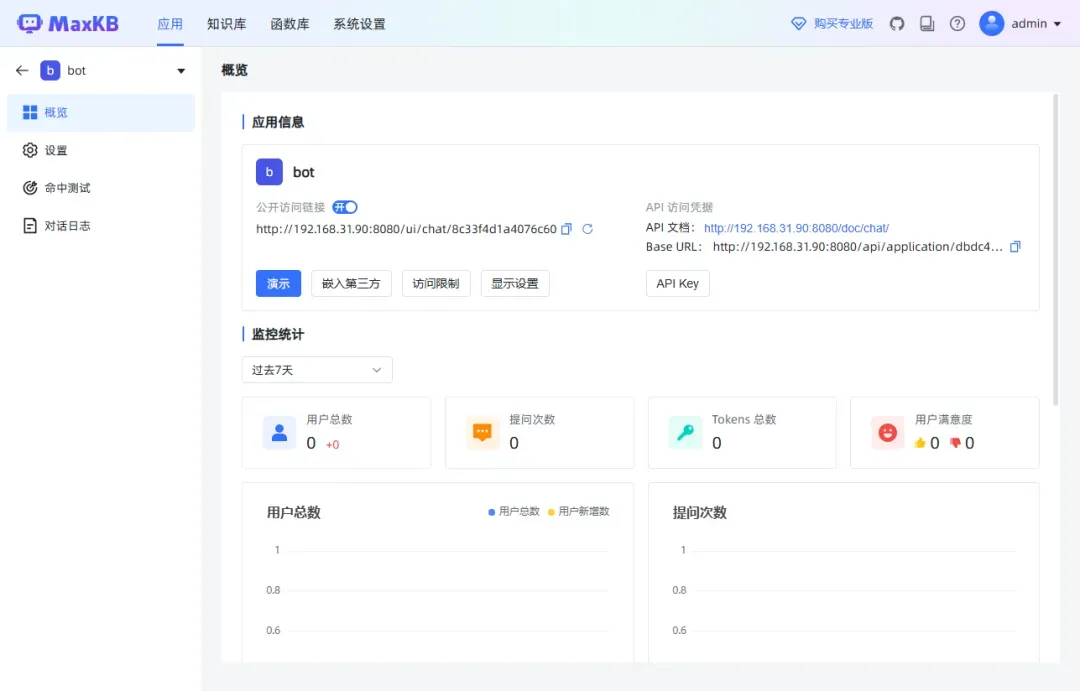
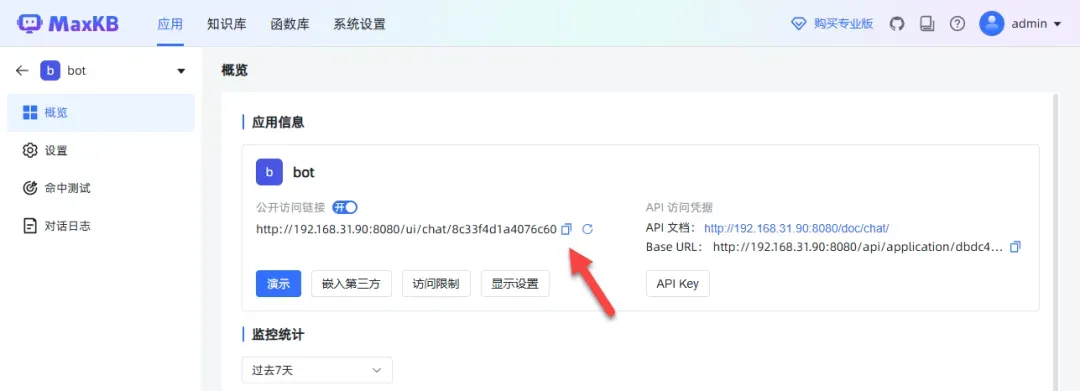
访问该链接以体验知识库的聊天机器人功能。
命中测试可以通过调节参数进行优化。
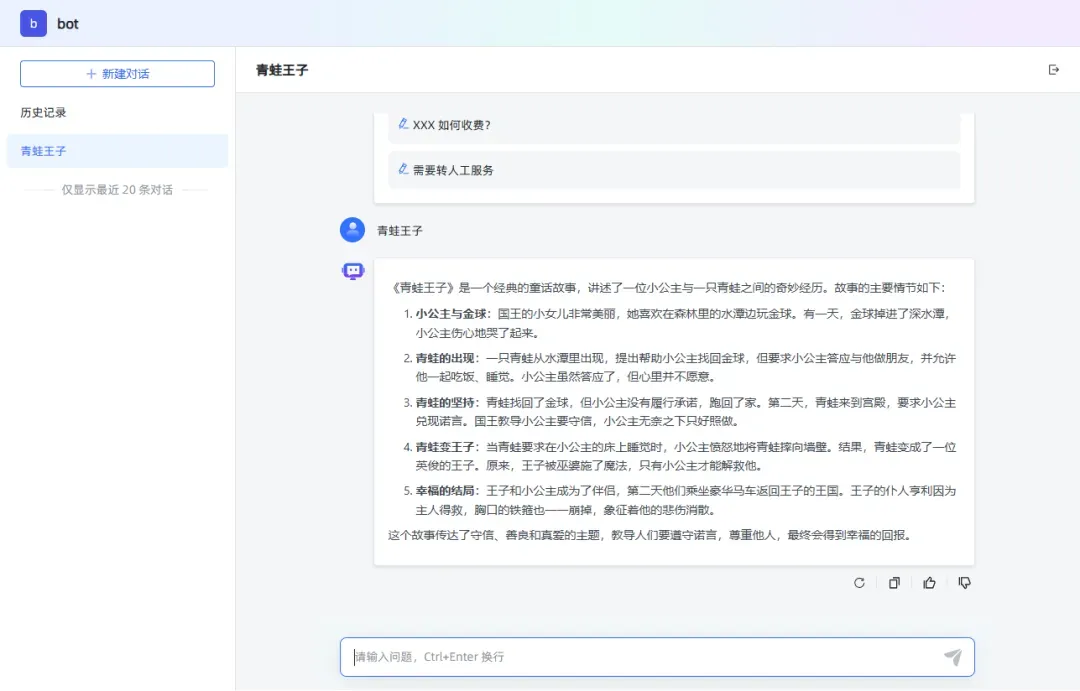
聊天记录会记录提问和回答的全过程。
总结
总的来说,我强烈推荐大家尝试部署MaxKB。对于初次接触知识库的用户而言,上手难度极低。整个流程清晰明了,只需上传文档并选择模型,即可快速创建应用。系统界面设计美观,布局合理,各项设置选项一目了然,用户可顺畅操作。