
尽管旋转拨号电话在数十年前已逐渐退出历史舞台,但无数人仍对其独特魅力记忆犹新。这些经典设备实际上可被改造为功能强大的ChatGPT热线。由Pollux Labs主导的这一创新项目,通过树莓派将复古电话与现代AI无缝连接:只需提起听筒并拨号,即可体验人工智能驱动的实时对话,完美复刻传统通话时代的沉浸感。
树莓派在此方案中承担核心角色,负责语音识别、文本生成及语音播放三大关键功能,而ChatGPT则能完整记忆通话中的每句对话。这种组合创造了一种独特交互体验——老式机械拨号与现代尖端人工智能的巧妙碰撞。接下来,我们将逐步解析实现这一魔法热线的完整过程。

为何选择旋转电话打造ChatGPT热线:复古情怀与技术创新
许多人钟爱旋转电话的怀旧触感——尽管通话内容完全现代化,但其独特的拨号声效与厚重手感能瞬间唤起往昔回忆。ChatGPT的加入更带来趣味十足的语音交互体验,与键盘输入截然不同。此外,将电话的扬声器、麦克风及拨号盘集成到树莓派的过程本身就是一场精彩的工程挑战。该项目不仅实现了旧技术的创造性重生,更开辟了软硬件结合的学习新途径。
通过电话听筒接收ChatGPT的实时回应可极大激发创造力。用户可预先整合音乐播放、新闻更新或引入其他AI服务,再逐步过渡到语音助手功能。实践始终是掌握技能的核心,此项目同步探索了硬件改装与软件开发的双重维度,充分展现了基础电子设备的惊人可塑性。最重要的是,旋转拨号与AI对话的结合将为每位体验者带来意想不到的惊喜与愉悦感。
改造ChatGPT热线必备清单:硬件与软件详解
首先需准备一部内部空间充裕的旋转拨号电话,确保能容纳树莓派及布线系统。70或80年代的电话型号通常具备较大腔体,便于整理线缆而无需额外钻孔。硬件方面,至少需要一台树莓派4B,但树莓派5将提供更优性能表现。
音频组件不可或缺:需配置麦克风捕捉用户语音,并将树莓派音频输出接入电话扬声器。推荐使用USB领夹麦克风或微型USB麦克风适配器,确保其能完美嵌入机壳内部空间。
可能有人疑问为何不直接使用听筒内置麦克风。实际测试表明,传统旋转电话的模拟麦克风难以适配现代数字系统,改造过程异常复杂。
电子工具包同样关键:包括烙铁、剪线钳和万用表等。这些工具将协助确认拨号脉冲线路、测试连接稳定性,并将树莓派音频输出精准接入扬声器线路。还需准备与树莓派GPIO引脚兼容的跳线或连接器,以及用于检测听筒摘挂状态的小型按钮。
软件层面需安装Python核心库:涵盖语音识别、文本转语音及OpenAI API集成模块。获取OpenAI API密钥并在Python脚本中引用,这是生成ChatGPT响应的技术基础。
逐步构建指南:从拆卸到AI热线部署
将传统电话改造为ChatGPT热线涉及精密布线及软件配置。本指南将系统演示如何拆解电话、识别拨号脉冲,并设置树莓派实现语音文本双向转换。请严格验证每根电线与引脚对应关系——任何错位都可能导致系统故障。
移除电话外壳,定位扬声器线路、旋转拨号线路及可用于连接挂钩状态检测按钮的区域。

剥离3.5毫米音频线外皮,将2.8毫米平板连接器焊接到听筒地线及声道线。随后将其接入听筒连接插座。


在电话内部固定USB麦克风(或适配器),确保树莓派能清晰捕获语音信号。

使用万用表确认拨号脉冲承载线路。将这些线路连接至GPIO引脚和地线。随后连接挂钩按钮,使软件能实时感知听筒状态变化。

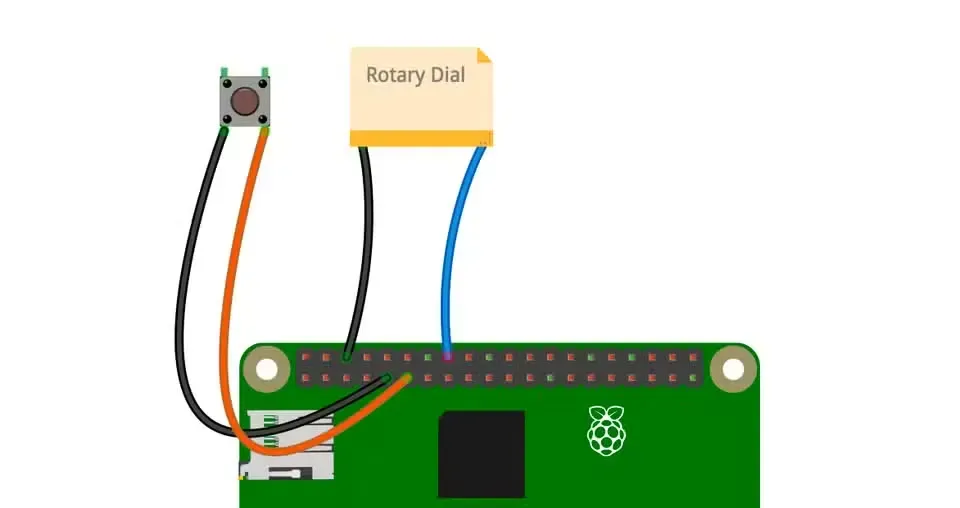

在树莓派安装关键音频库:包括PyAudio、PyGame及OpenAI客户端。下载或创建拨号音等音频文件,并将OpenAI密钥存储于.env配置文件。
编写核心Python脚本:用于麦克风音频捕获、ChatGPT请求发送及电话扬声器的AI响应播放。可自主开发或采用Pollux Labs提供的脚本框架,但需根据实际需求调整GPIO引脚编号、音频参数及定制化文本提示。
手动运行脚本验证功能完整性。当成功听到拨号音且ChatGPT对语音指令做出响应后,添加系统服务实现树莓派启动时自动激活热线功能。
若需参考完整实现,以下是核心脚本代码:
#!/usr/bin/env python3"""ChatGPT for Rotary Phonehttps://en.polluxlabs.netMIT LicenseCopyright (c) 2025 Frederik KumbartzkiPermission is hereby granted, free of charge, to any person obtaining a copyof this software and associated documentation files (the "Software"), to dealin the Software without restriction, including without limitation the rightsto use, copy, modify, merge, publish, distribute, sublicense, and/or sellcopies of the Software, and to permit persons to whom the Software isfurnished to do so, subject to the following conditions:The above copyright notice and this permission notice shall be included in allcopies or substantial portions of the Software.THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS ORIMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THEAUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHERLIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THESOFTWARE."""import osimport sysimport timeimport threadingfrom queue import Queuefrom pathlib import PathAudio and speech librariesos.environ['PYGAME_HIDE_SUPPORT_PROMPT'] = "hide"import pygameimport pyaudioimport numpy as npimport wavefrom openai import OpenAIOpenAI API Keyfrom dotenv import load_dotenvload_dotenv()OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")if not OPENAI_API_KEY: print("Error: OPENAI_API_KEY not found.") sys.exit(1)Hardware librariesfrom gpiozero import ButtonConstants and configurationsAUDIO_DIR = "/home/pi/Desktop/callGPT"AUDIO_FILES = { "tone": f"{AUDIO_DIR}/a440.mp3", "try_again": f"{AUDIO_DIR}/tryagain.mp3", "error": f"{AUDIO_DIR}/error.mp3"}DIAL_PIN = 23 # GPIO pin for rotary dialSWITCH_PIN = 17 # GPIO pin for hook switchAudio parametersAUDIO_FORMAT = pyaudio.paInt16CHANNELS = 1SAMPLE_RATE = 16000CHUNK_SIZE = 1024SILENCE_THRESHOLD = 500MAX_SILENCE_CHUNKS = 20 # About 1.3 seconds of silenceDEBOUNCE_TIME = 0.1 # Time in seconds for debouncing button inputsclass AudioManager: """Manages audio playback and recording.""" def __init__(self): pygame.mixer.init(frequency=44100, buffer=2048) self.playing_audio = False self.audio_thread = NoneCreate temp directory self.temp_dir = Path(__file__).parent / "temp_audio" self.temp_dir.mkdir(exist_ok=True)Preload sounds self.sounds = {} for name, path in AUDIO_FILES.items(): try: self.sounds[name] = pygame.mixer.Sound(path) except: print(f"Error loading {path}") def play_file(self, file_path, wait=True): try: sound = pygame.mixer.Sound(file_path) channel = sound.play() if wait and channel: while channel.get_busy(): pygame.time.Clock().tick(30) except: pygame.mixer.music.load(file_path) pygame.mixer.music.play() if wait: while pygame.mixer.music.get_busy(): pygame.time.Clock().tick(30) def start_continuous_tone(self): self.playing_audio = True if self.audio_thread and self.audio_thread.is_alive(): self.playing_audio = False self.audio_thread.join(timeout=1.0) self.audio_thread = threading.Thread(target=self._play_continuous_tone) self.audio_thread.daemon = True self.audio_thread.start() def _play_continuous_tone(self): try: if "tone" in self.sounds: self.sounds["tone"].play(loops=-1) while self.playing_audio: time.sleep(0.1) self.sounds["tone"].stop() else: pygame.mixer.music.load(AUDIO_FILES["tone"]) pygame.mixer.music.play(loops=-1) while self.playing_audio: time.sleep(0.1) pygame.mixer.music.stop() except Exception as e: print(f"Error during tone playback: {e}") def stop_continuous_tone(self): self.playing_audio = False if "tone" in self.sounds: self.sounds["tone"].stop() if pygame.mixer.get_init() and pygame.mixer.music.get_busy(): pygame.mixer.music.stop()class SpeechRecognizer: """Handles real-time speech recognition using OpenAI's Whisper API.""" def __init__(self, openai_client): self.client = openai_client self.audio = pyaudio.PyAudio() self.stream = None def capture_and_transcribe(self):Setup audio stream if not already initialized if not self.stream: self.stream = self.audio.open( format=AUDIO_FORMAT, channels=CHANNELS, rate=SAMPLE_RATE, input=True, frames_per_buffer=CHUNK_SIZE, )Set up queue and threading audio_queue = Queue() stop_event = threading.Event()Start audio capture thread capture_thread = threading.Thread( target=self._capture_audio, args=(audio_queue, stop_event) ) capture_thread.daemon = True capture_thread.start()Process the audio result = self._process_audio(audio_queue, stop_event)Cleanup stop_event.set() capture_thread.join() return result def _capture_audio(self, queue, stop_event): while not stop_event.is_set(): try: data = self.stream.read(CHUNK_SIZE, exception_on_overflow=False) queue.put(data) except KeyboardInterrupt: break def _process_audio(self, queue, stop_event): buffer = b"" speaking = False silence_counter = 0 while not stop_event.is_set(): if not queue.empty(): chunk = queue.get()Check volume data_np = np.frombuffer(chunk, dtype=np.int16) volume = np.abs(data_np).mean()Detect speaking if volume > SILENCE_THRESHOLD: speaking = True silence_counter = 0 elif speaking: silence_counter += 1Add chunk to buffer buffer += chunkProcess if we've detected end of speech if speaking and silence_counter > MAX_SILENCE_CHUNKS: print("Processing speech...")Save to temp file temp_file = Path(__file__).parent / "temp_recording.wav" self._save_audio(buffer, temp_file)Transcribe try: return self._transcribe_audio(temp_file) except Exception as e: print(f"Error during transcription: {e}") buffer = b"" speaking = False silence_counter = 0 return None def _save_audio(self, buffer, file_path): with wave.open(str(file_path), "wb") as wf: wf.setnchannels(CHANNELS) wf.setsampwidth(self.audio.get_sample_size(AUDIO_FORMAT)) wf.setframerate(SAMPLE_RATE) wf.writeframes(buffer) def _transcribe_audio(self, file_path): with open(file_path, "rb") as audio_file: transcription = self.client.audio.transcriptions.create( model="whisper-1", file=audio_file, language="en" ) return transcription.text def cleanup(self): if self.stream: self.stream.stop_stream() self.stream.close() self.stream = None if self.audio: self.audio.terminate() self.audio = Noneclass ResponseGenerator: """Generates and speaks streaming responses from OpenAI's API.""" def __init__(self, openai_client, temp_dir): self.client = openai_client self.temp_dir = temp_dir self.answer = "" def generate_streaming_response(self, user_input, conversation_history=None): self.answer = "" collected_messages = [] chunk_files = []Audio playback queue and control variables audio_queue = Queue() playing_event = threading.Event() stop_event = threading.Event()Start the audio playback thread playback_thread = threading.Thread( target=self._audio_playback_worker, args=(audio_queue, playing_event, stop_event) ) playback_thread.daemon = True playback_thread.start()Prepare messages messages = [ {"role": "system", "content": "You are a humorous conversation partner engaged in a natural phone call. Keep your answers concise and to the point."} ]Use conversation history if available, but limit to last 4 pairs if conversation_history and len(conversation_history) > 0: if len(conversation_history) > 8: conversation_history = conversation_history[-8:] messages.extend(conversation_history) else: messages.append({"role": "user", "content": user_input})Stream the response stream = self.client.chat.completions.create( model="gpt-4o-mini", messages=messages, stream=True )Variables for sentence chunking sentence_buffer = "" chunk_counter = 0 for chunk in stream: if chunk.choices and hasattr(chunk.choices[0], 'delta') and hasattr(chunk.choices[0].delta, 'content'): content = chunk.choices[0].delta.content if content: collected_messages.append(content) sentence_buffer += contentProcess when we have a complete sentence or phrase if any(end in content for end in [".", "!", "?", ":"]) or len(sentence_buffer) > 100:Generate speech for this chunk chunk_file_path = self.temp_dir / f"chunk_{chunk_counter}.mp3" try:Generate speech response = self.client.audio.speech.create( model="tts-1", voice="alloy", input=sentence_buffer, speed=1.0 ) response.stream_to_file(str(chunk_file_path)) chunk_files.append(str(chunk_file_path))Add to playback queue audio_queue.put(str(chunk_file_path))Signal playback thread if it's waiting playing_event.set() except Exception as e: print(f"Error generating speech for chunk: {e}")Reset buffer and increment counter sentence_buffer = "" chunk_counter += 1Process any remaining text if sentence_buffer.strip(): chunk_file_path = self.temp_dir / f"chunk_{chunk_counter}.mp3" try: response = self.client.audio.speech.create( model="tts-1", voice="alloy", input=sentence_buffer, speed=1.2 ) response.stream_to_file(str(chunk_file_path)) chunk_files.append(str(chunk_file_path)) audio_queue.put(str(chunk_file_path)) playing_event.set() except Exception as e: print(f"Error generating final speech chunk: {e}")Signal end of generation audio_queue.put(None) # Sentinel to signal end of queueWait for playback to complete playback_thread.join() stop_event.set() # Ensure the thread stopsCombine all messages self.answer = "".join(collected_messages) print(self.answer)Clean up temp files self._cleanup_temp_files(chunk_files) return self.answer def _audio_playback_worker(self, queue, playing_event, stop_event): while not stop_event.is_set():Wait for a signal that there's something to play if queue.empty(): playing_event.wait(timeout=0.1) playing_event.clear() continueGet the next file to play file_path = queue.get()None is our sentinel value to signal end of queue if file_path is None: break try:Play audio and wait for completion pygame.mixer.music.load(file_path) pygame.mixer.music.play()Wait for playback to complete before moving to next chunk while pygame.mixer.music.get_busy() and not stop_event.is_set(): pygame.time.Clock().tick(30)Small pause between chunks for more natural flow time.sleep(0.05) except Exception as e: print(f"Error playing audio chunk: {e}") def _cleanup_temp_files(self, file_list):Wait a moment to ensure files aren't in use time.sleep(0.5) for file_path in file_list: try: if os.path.exists(file_path): os.remove(file_path) except Exception as e: print(f"Error removing temp file: {e}")class RotaryDialer: """Handles rotary phone dialing and services.""" def __init__(self, openai_client): self.client = openai_client self.audio_manager = AudioManager() self.speech_recognizer = SpeechRecognizer(openai_client) self.response_generator = ResponseGenerator(openai_client, self.audio_manager.temp_dir)Set up GPIO self.dial_button = Button(DIAL_PIN, pull_up=True) self.switch = Button(SWITCH_PIN, pull_up=True)State variables self.pulse_count = 0 self.last_pulse_time = 0 self.running = True def start(self):Set up callbacks self.dial_button.when_pressed = self._pulse_detected self.switch.when_released = self._handle_switch_released self.switch.when_pressed = self._handle_switch_pressedStart in ready state if not self.switch.is_pressed:Receiver is picked up self.audio_manager.start_continuous_tone() else:Receiver is on hook print("Phone in idle state. Pick up the receiver to begin.") print("Rotary dial ready. Dial a number when the receiver is picked up.") try: self._main_loop() except KeyboardInterrupt: print("Terminating...") self._cleanup() def _main_loop(self): while self.running: self._check_number() time.sleep(0.1) def _pulse_detected(self): if not self.switch.is_pressed: current_time = time.time() if current_time - self.last_pulse_time > DEBOUNCE_TIME: self.pulse_count += 1 self.last_pulse_time = current_time def _check_number(self): if not self.switch.is_pressed and self.pulse_count > 0: self.audio_manager.stop_continuous_tone() time.sleep(1.5) # Wait between digits if self.pulse_count == 10: self.pulse_count = 0 # "0" is sent as 10 pulses print("Dialed service number:", self.pulse_count) if self.pulse_count == 1: self._call_gpt_service()Return to dial tone after conversation if not self.switch.is_pressed: # Only if the receiver wasn't hung up self._reset_state() self.pulse_count = 0 def _call_gpt_service(self):Conversation history for context conversation_history = [] first_interaction = TrueFor faster transitions speech_recognizer = self.speech_recognizer response_generator = self.response_generatorPreparation for next recording next_recording_thread = None next_recording_queue = Queue()Conversation loop - runs until the receiver is hung up while not self.switch.is_pressed:If there's a prepared next recording thread, use its result if next_recording_thread: next_recording_thread.join() recognized_text = next_recording_queue.get() next_recording_thread = None else:Only during first iteration or as fallback print("Listening..." + (" (Speak now)" if first_interaction else "")) first_interaction = FalseStart audio processing recognized_text = speech_recognizer.capture_and_transcribe() if not recognized_text: print("Could not recognize your speech") self.audio_manager.play_file(AUDIO_FILES["try_again"]) continue print("Understood:", recognized_text)Update conversation history conversation_history.append({"role": "user", "content": recognized_text})Start the next recording thread PARALLEL to API response next_recording_thread = threading.Thread( target=self._background_capture, args=(speech_recognizer, next_recording_queue) ) next_recording_thread.daemon = True next_recording_thread.start()Generate the response response = response_generator.generate_streaming_response(recognized_text, conversation_history)Add response to history conversation_history.append({"role": "assistant", "content": response})Check if the receiver was hung up in the meantime if self.switch.is_pressed: breakIf we get here, the receiver was hung up if next_recording_thread and next_recording_thread.is_alive(): next_recording_thread.join(timeout=0.5) def _background_capture(self, recognizer, result_queue): try: result = recognizer.capture_and_transcribe() result_queue.put(result) except Exception as e: print(f"Error in background recording: {e}") result_queue.put(None) def _reset_state(self): self.pulse_count = 0 self.audio_manager.stop_continuous_tone() self.audio_manager.start_continuous_tone() print("Rotary dial ready. Dial a number.") def _handle_switch_released(self): print("Receiver picked up - System restarting") self._restart_script() def _handle_switch_pressed(self): print("Receiver hung up - System terminating") self._cleanup() self.running = FalseComplete termination after short delay threading.Timer(1.0, self._restart_script).start() return def _restart_script(self): print("Script restarting...") self.audio_manager.stop_continuous_tone() os.execv(sys.executable, ['python'] + sys.argv) def _cleanup(self):Terminate Audio Manager self.audio_manager.stop_continuous_tone()Terminate Speech Recognizer if it exists if hasattr(self, 'speech_recognizer') and self.speech_recognizer: self.speech_recognizer.cleanup() print("Resources have been released.")def main():Initialize OpenAI client client = OpenAI(api_key=OPENAI_API_KEY)Create and start the rotary dialer dialer = RotaryDialer(client) dialer.start() print("Program terminated.")if name == "__main__": main()完成所有连接与配置后,建议系统性回顾优化点。不同电话型号存在细节差异,可能需针对性调试。初始阶段在电话外壳内为树莓派供电,可简化故障排查流程。当成功通过听筒听到ChatGPT回应时,标志你的旋转电话热线已基本构建完成。
融合复古与现代:AI对话的创意延展

用ChatGPT赋能老式旋转电话,完美融合怀旧情感与前沿创新。这种AI拨号体验生动演绎了历史技术与当代科技的神奇互动。未来可通过调整语音类型、语言支持或定制提示词,个性化优化ChatGPT响应模式。
项目还支持扩展整合更多AI服务——如新闻播报、播客流媒体或智能日程管理。该项目不仅是电子改装与Python编程的实践课堂,更弥合了模拟设备与数字智能的鸿沟。最终你将获得一部功能完备的旋转电话,化身全天候ChatGPT热线。尽享这场复古未来主义对话盛宴,持续探索AI伙伴的全新可能性。