
在本指南中,我们将探索如何在阿里云的ACK上进行DeepSeek-R1模型的私有化部署,并通过使用Karpenter 阿里云Provider动态扩缩GPU节点资源,显著降低云计算预算。
GitHub 地址:
https://github.com/cloudpilot-ai/karpenter-provider-alibabacloud
借助Karpenter的自动调度能力,我们可以根据实时需求灵活调整计算资源(如竞价实例),确保模型推理的高效运行,同时最大限度地优化成本。

第一部分:为什么选择在K8s上私有化部署DeepSeek-R1模型
在阿里云ACK上部署DeepSeek模型有以下几个重要优势:
首先,许多大型企业在部署AI模型时通常需要确保数据的私有性,这一点在处理敏感信息或关键业务时尤为重要。
其次,Kubernetes提供灵活的底层计算资源管理,企业可以根据实际需求进行资源的调度、分配与优化。借助阿里云ACK集群,企业能够精确管理计算资源,并进行定制配置,以确保模型训练和推理任务在最合适的GPU资源上高效进行。
此外,私有部署显著减少了系统宕机和服务不可用的风险(如下图所示),确保系统的高可用性。同时,它不受敏感词等外部因素的约束,进一步增强了灵活性和自主控制能力。

第二部分:如何创建ACK集群
本文将使用Terraform轻松地创建ACK集群,选择区域为ap-northeast-2(首尔)。
详细创建步骤请参考:
https://github.com/cloudpilot-ai/examples/tree/main/clusters/ack-spot-flannel
第三部分:安装Karpenter
请参考官方安装文档进行Karpenter的安装(仅需完成前五步):
同时,部署NodePool和NodeClass,以定义弹性GPU节点的配置:
# nodepool.yaml
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: ecsnodepool
spec:
disruption:
budgets:
- nodes: 95%
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 1m
template:
spec:
requirements:
- key: node.kubernetes.io/instance-type
operator: In
values:
- "ecs.gn7i-c8g1.2xlarge"
- "ecs.gn7i-c16g1.4xlarge"
- "ecs.gn7i-2x.8xlarge"
- "ecs.gn7i-4x.8xlarge"
- "ecs.gn7i-c32g1.8xlarge"
- "ecs.gn7i-c48g1.12xlarge"
- "ecs.gn7i-c56g1.14xlarge"
- "ecs.gn7i-c32g1.16xlarge"
- "ecs.gn7i-c32g1.32xlarge"
- key: kubernetes.io/arch
operator: In
values: [ "amd64" ]
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot"]
nodeClassRef:
group: "karpenter.k8s.alibabacloud"
kind: ECSNodeClass
name: defaultnodeclass
---
# nodeclass.yaml
apiVersion: karpenter.k8s.alibabacloud/v1alpha1
kind: ECSNodeClass
metadata:
name: defaultnodeclass
spec:
systemDisk:
size: 300
categories:
- cloud
- cloud_ssd
- cloud_efficiency
- cloud_essd
- cloud_auto
- cloud_essd_entry
vSwitchSelectorTerms:
- tags:
karpenter.sh/discovery: "deepseek" # 替换为你的集群名称
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "deepseek" # 替换为你的集群名称
imageSelectorTerms:
- alias: AlibabaCloudLinux3
在NodePool中,node.kubernetes.io/instance-type用于定义候选节点类型,这里利用了A10 GPU。通过使用karpenter.sh/capacity-type将节点计费类型设定为Spot,这样能够节省高达85%的费用,甚至低于包年费用(375,853.84元)。未来结合HPA的自动扩缩容策略,预计还能够进一步降低成本。
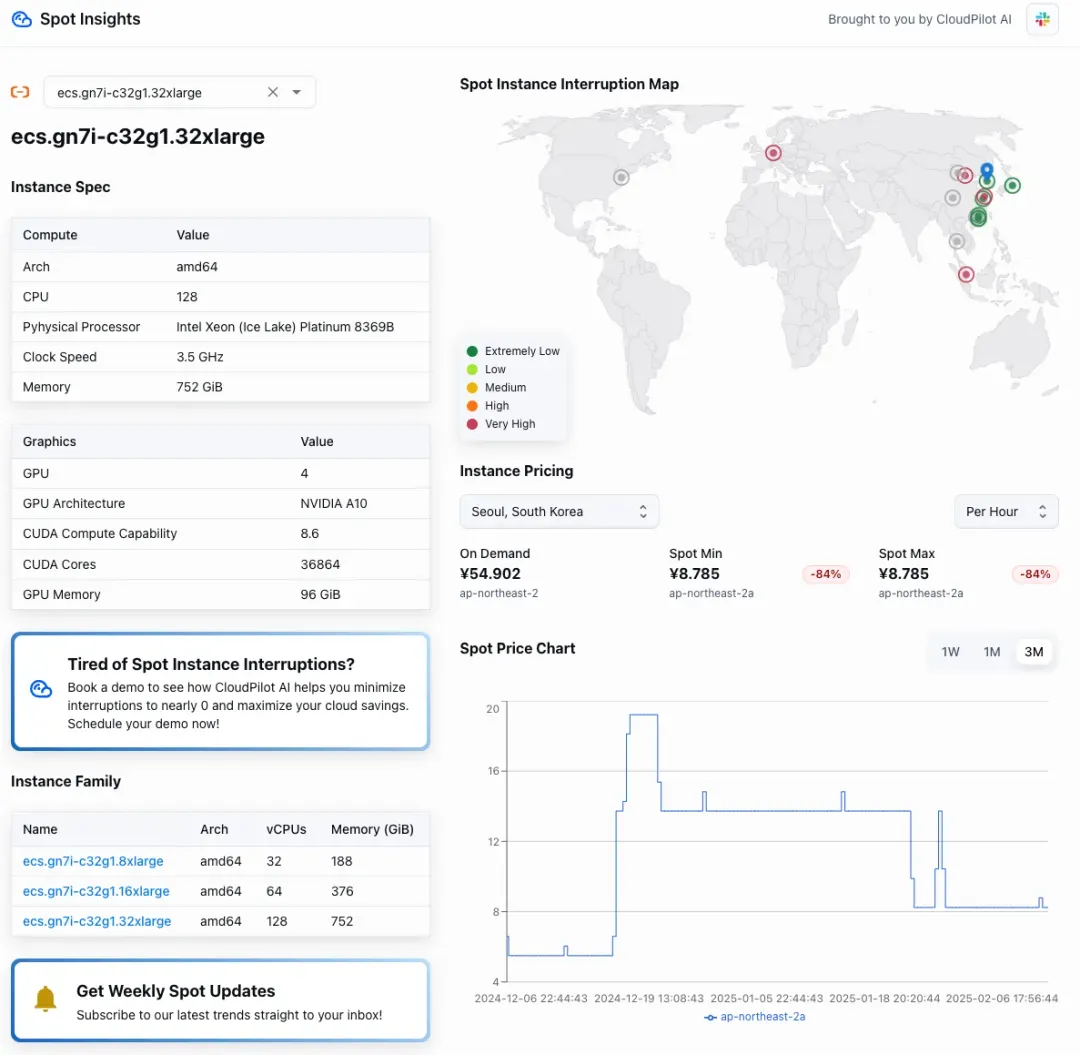
数据来源:spot.cloudpilot.ai
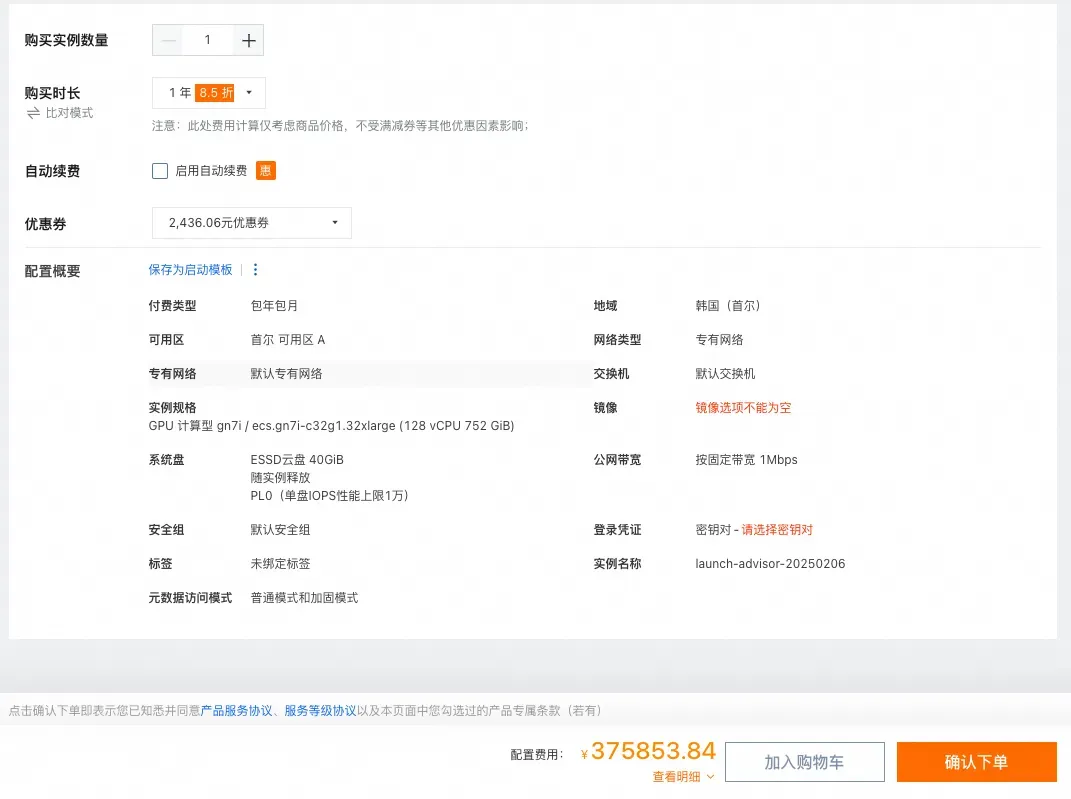
NOTE: 若要查阅计费数据详情,请访问:
https://spot.cloudpilot.ai/alibabacloud?instance=ecs.gn7i-c32g1.32xlarge#region=ap-northeast-2
安装Karpenter后,执行以下命令完成部署:
kubectl apply -f nodepool.yaml
kubectl apply -f nodeclass.yaml
观察NodePool状态,READY显示为True即表示成功:
NAME NODECLASS NODES READY AGE
ecsnodepool defaultnodeclass 1 True 3h10m
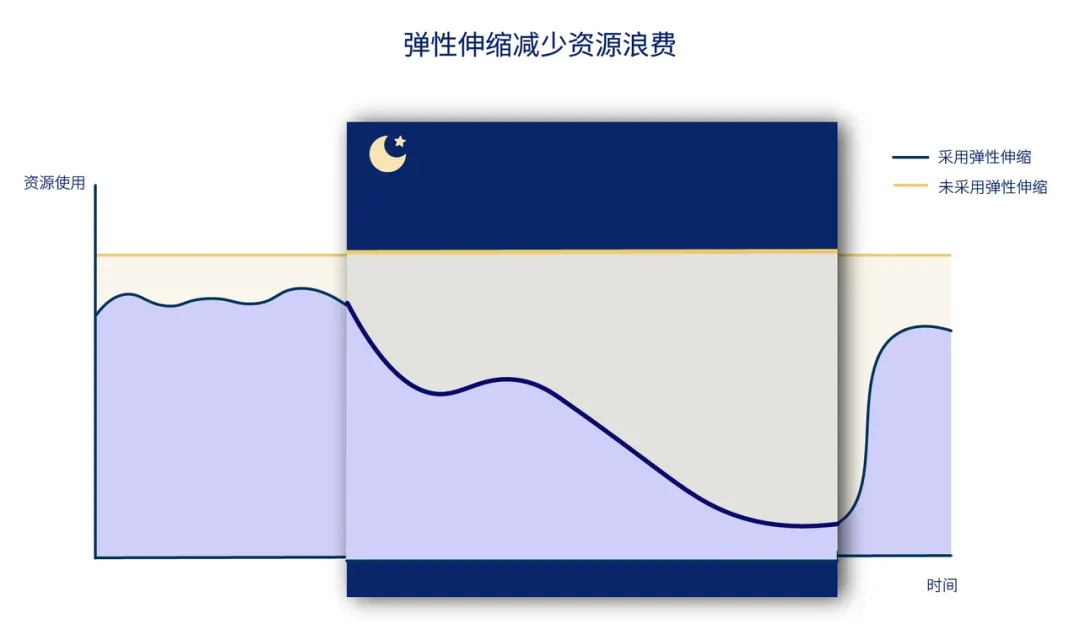
在业务流量高峰期,系统能够充分利用GPU资源满足计算需求,而在请求低谷时,闲置资源若仍在运行,将导致不必要的成本浪费。
假如一天中仅有8小时面对流量高峰,采用弹性策略的用户可根据实际负载动态调整资源,在低负载的16小时内自动缩容Pod至0,释放闲置的GPU资源,至少能节省60%的云成本。
第四部分:部署DeepSeek-R1模型
1. 创建YAML文件
创建一个名为deepseek.yaml的文件,其内容如下,你也可以修改deepseek-ai/DeepSeek-R1-Distill-Qwen-32B为你选定的其他模型:
apiVersion: v1
kind: Namespace
metadata:
name: deepseek
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deepseek-deployment
namespace: deepseek
labels:
app: deepseek
spec:
replicas: 1
selector:
matchLabels:
app: deepseek
template:
metadata:
labels:
app: deepseek
spec:
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
volumes:
- name: cache-volume
hostPath:
path: /tmp/deepseek
type: DirectoryOrCreate
- name: shm
emptyDir:
medium: Memory
sizeLimit: "2Gi"
containers:
- name: deepseek
image: cloudpilotai-registry.cn-hangzhou.cr.aliyuncs.com/cloudpilotai/vllm-openai:latest
command: ["/bin/sh", "-c"]
args: [
"vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --max_model_len 2048 --tensor-parallel-size 4"
]
env:
- name: HF_HUB_ENABLE_HF_TRANSFER
value: "0"
ports:
- containerPort: 8000
resources:
requests:
nvidia.com/gpu: "4"
limits:
nvidia.com/gpu: "4"
volumeMounts:
- mountPath: /root/.cache/huggingface
name: cache-volume
- name: shm
mountPath: /dev/shm
---
apiVersion: v1
kind: Service
metadata:
name: deepseek-svc
namespace: deepseek
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8000
selector:
app: deepseek
type: ClusterIP
在此配置中,--tensor-parallel-size 4 参数意味着使用单机4张GPU进行并行推理(也可以选择单张GPU,虽然速度会略慢)。
以下是不同参数对显卡和显存需求的说明,用户可以根据自身需求选择合适的GPU计算资源:
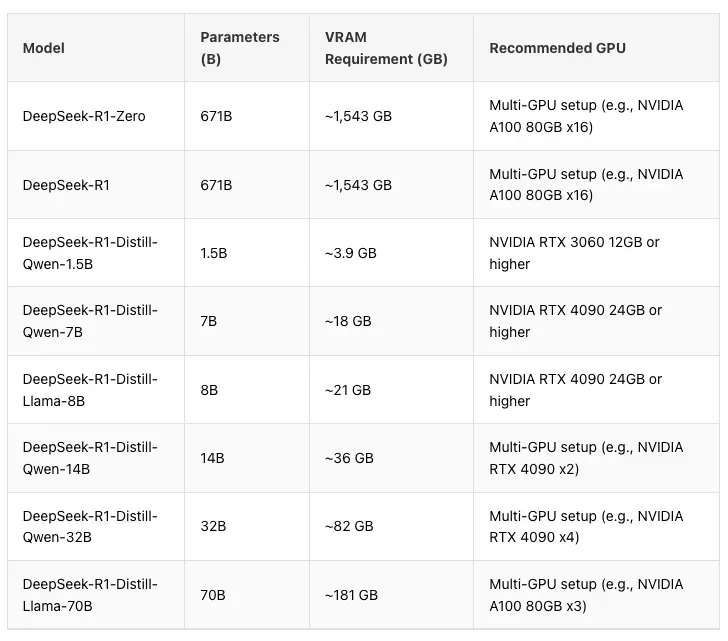
2. 部署YAML
执行以下命令以部署服务:
kubectl apply -f deepseek.yaml
此时,Karpenter将依据4卡GPU的需求创建4卡的Spot单节点(4卡并行,以提升Token的响应速度):
$ kubectl get nodeclaim -A
NAME TYPE CAPACITY ZONE NODE READY AGE
ecsnodepool-knc9p ecs.gn7i-c32g1.32xlarge spot ap-northeast-2c ap-northeast-2.172.16.2.174 True 136m
稍等片刻,查看相关Pod日志,若显示如下内容则表示准备完成:
...
INFO 02-05 05:16:52 launcher.py:27] Route: /invocations, Methods: POST
INFO: Started server process [7]
INFO: Waiting for application startup.
INFO: Application startup complete.
...
3. 使用UI进行聊天交互
首先运行以下命令,将服务在本地暴露出来:
kubectl port-forward svc/deepseek-svc -n deepseek 8080:80
然后,访问网址:https://app.nextchat.dev/,并在左下角进行配置:
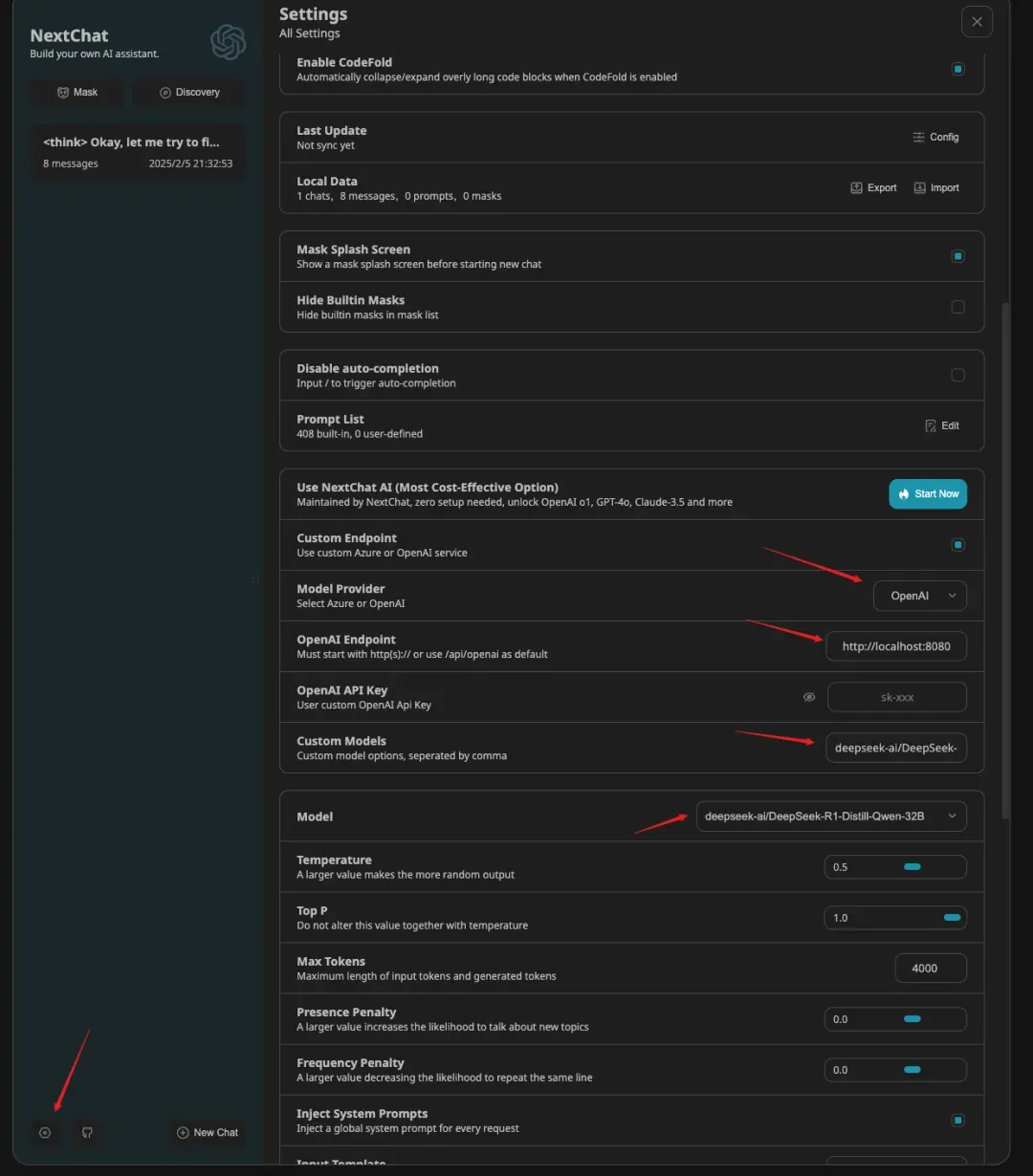
依次输入和选择:
- OpenAI
- http://localhost:8080
- deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
- deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
最后,你可通过聊天窗口使用DeepSeek-R1模型,体验A10四卡的迅速响应。
第五部分:总结
经过初步体验,我们发现结合Karpenter在Kubernetes环境中可迅速启动所需的GPU节点资源。尽管此指南仅为初步尝试,若想实现生产级的部署,还需解决以下问题:
- 镜像加速: 避免经常无法快速拉取镜像,例如可以使用Dragonfly等工具。
- 模型文件加载加速: 防止长时间模型文件下载。
- 对超大模型的支持: 通常超大模型需要多个节点才能运行,需要配置vLLM进行多节点和多GPU推理。
- 动态扩缩容: 根据请求量动态调整Pod数量以应对请求波动;在长时间无请求时将Pod缩容至0,释放闲置的GPU资源,进而节省成本。