
关键词: Hugging Face, Transformers, Chat-UI, LLM, ChatGPT, MongoDB, 前端部署, 聊天应用
上一篇文章介绍了Text Generation Inference这个后端项目,那么本文接下去将与之搭配的前端项目chat-ui做下介绍。
Hugging Chat UI 是一个开源的聊天工具,大家在这里可以尝试使用开源的大型语言模型,如 Falcon、StableCode及Llama 2等。本文将给大家介绍一下如何配置部署Chat-UI这个开源项目。
hugging face chat-ui项目地址:https://github.com/huggingface/chat-ui
hugging face官方部署的demo: https://huggingface.co/chat/
界面的截图:
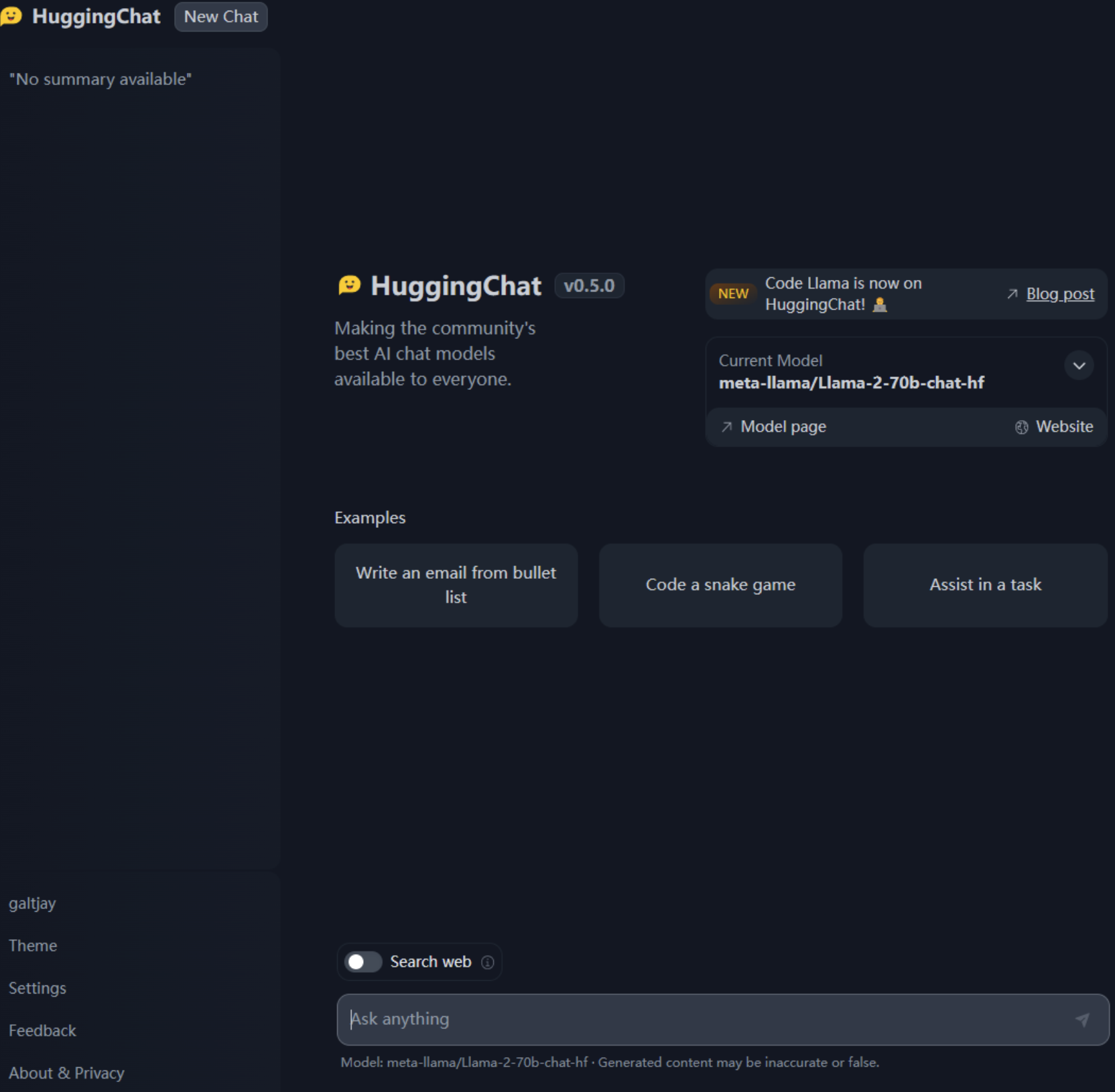
前端的项目其实没啥好讲的直接进入到部署:
这个项目依赖MongoDB 存储会话历史,因此先在本地搭建一个MongoDB :
docker run -d -p 27017:27017 --name mongo-chatui mongo:latest
docker-compsoe:
version: '3'
services:
mongo-chatui:
image: mongo:latest
container_name: mongo-chatui
ports:
- "27017:27017"
进行前端项目的配置及打包:
首先git clone https://github.com/huggingface/chat-ui.git
进入到项目文件夹chat-ui,项目的核心配置都放置在.env文件中,将.env复制一份.env.local进行配置的修改:
1. 首先需要更改最基础的两个配置
MONGODB_URL=mongodb://localhost:27017
HF_ACCESS_TOKEN=hf_TiNiTzAUnMSyyBnXPKZfCXXXXYYYYYZZZZ
2.修改MODELS中,models的定义,此处给出一个基于text-generation-inference本地部署的示例配置,供大家参考。主要新增endpoints字段。
{
"name": "stabilityai/stablecode-instruct-alpha-3b",
"endpoints":[{"url": "http://127.0.0.1:8080/generate_stream"}],
"datasetName": "stabilityai/stablecode-instruct-alpha-3b",
"description": "StableCode",
"websiteUrl": "https://huggingface.co/stabilityai/stablecode-instruct-alpha-3b",
"userMessageToken": "<|prompter|>",
"assistantMessageToken": "<|assistant|>",
"messageEndToken": "</s>",
"preprompt": "Below are a series of dialogues between various people and an AI assistant. The AI tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble-but-knowledgeable. The assistant is happy to help with almost anything, and will do its best to understand exactly what is needed. It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer. That said, the assistant is practical and really does its best, and doesn't let caution get too much in the way of being useful.\n-----\n",
"promptExamples": [
{
"title": "Write an email from bullet list",
"prompt": "As a restaurant owner, write a professional email to the supplier to get these products every week: \n\n- Wine (x10)\n- Eggs (x24)\n- Bread (x12)"
}, {
"title": "Code a snake game",
"prompt": "Code a basic snake game in python, give explanations for each step."
}, {
"title": "Assist in a task",
"prompt": "How do I make a delicious lemon cheesecake?"
}
],
"parameters": {
"temperature": 0.9,
"top_p": 0.95,
"repetition_penalty": 1.2,
"top_k": 50,
"truncate": 1000,
"max_new_tokens": 1024
}
}
3. 其他的一些配置
可以调整页面的主色调,项目的名称,内部的一些超链接信息。
可以进行本地、 OpenID、三方鉴权等配置。
配置完成之后:
npm install 安装依赖
npm run dev 在本地跑下测试
没有问题的话
npm run build 打包
将/build目录部署到nginx即可。
补充parameters的介绍:
temperature(温度):
作用:温度参数影响生成文本的多样性。
解释:较高的温度值(大于1.0)会增加模型生成文本的随机性,使生成的文本更加多样化。较低的温度值(小于1.0)会减少随机性,使生成的文本更加确定性和一致。
示例:较高温度(例如0.9)可能会生成不同的输出,包括一些不太常见的词语或短语,而较低温度(例如0.2)可能会生成更加常见和可预测的文本。
top_p(前p个词汇):
作用:控制生成文本中词汇的概率分布。
解释:top_p参数表示生成文本时,模型将考虑的概率分布中最高的概率词汇。它会动态选择概率分布中累积概率小于等于top_p的词汇,以生成文本。这有助于避免生成不合理或不相关的文本。
示例:设置top_p为0.95会让模型在生成文本时,只考虑累积概率最高的95%的词汇,从而提高文本的连贯性和合理性。
repetition_penalty(重复惩罚):
作用:控制生成文本中重复词汇的惩罚程度。
解释:repetition_penalty参数用于减少生成文本中重复的词汇。较高的值(大于1.0)会增加惩罚,鼓励生成更加多样化的文本。较低的值(小于1.0)会减少惩罚,允许生成文本中有一些重复的词汇。
示例:设置repetition_penalty为1.2会减少生成文本中相同词汇的频率,提高文本的多样性。
top_k(前k个词汇):
作用:限制生成文本中可考虑的词汇数量。
解释:top_k参数表示生成文本时,模型将仅考虑概率分布中最高的k个词汇,而忽略其他词汇。这可以用于限制生成文本的词汇多样性和复杂性。
示例:设置top_k为50会让模型仅考虑最高的50个概率最高的词汇,忽略其他词汇。
truncate(截断长度):
作用:限制生成文本的长度。
解释:truncate参数用于限制生成文本的总长度。如果生成的文本超过了指定的截断长度,模型将截断文本,以确保其不会太长。
示例:设置truncate为1000会确保生成文本的总长度不超过1000个标记(如词语或子词)。
max_new_tokens(最大新增标记):
作用:限制生成文本中新增标记的数量。
解释:max_new_tokens参数用于限制生成文本中新增标记的数量,确保生成的文本不会过长。它通常用于控制生成文本的长度。
示例:设置max_new_tokens为1024会限制生成文本中新增标记的数量不超过1024个。
关联阅读,后端项目text-generation-inference: