
The previous article introduced the backend project called "Text Generation Inference." In this article, we will provide an introduction to the accompanying frontend project, "chat-ui."
Hugging Chat UI is an open-source chat tool where you can experiment with using large language models like Falcon, StableCode, and Llama 2. This article will guide you on how to configure and deploy the open-source project Chat-UI.
Hugging Face Chat-UI project repository: https://github.com/huggingface/chat-ui
Official demo by Hugging Face: https://huggingface.co/chat/
Screenshots of the interface:
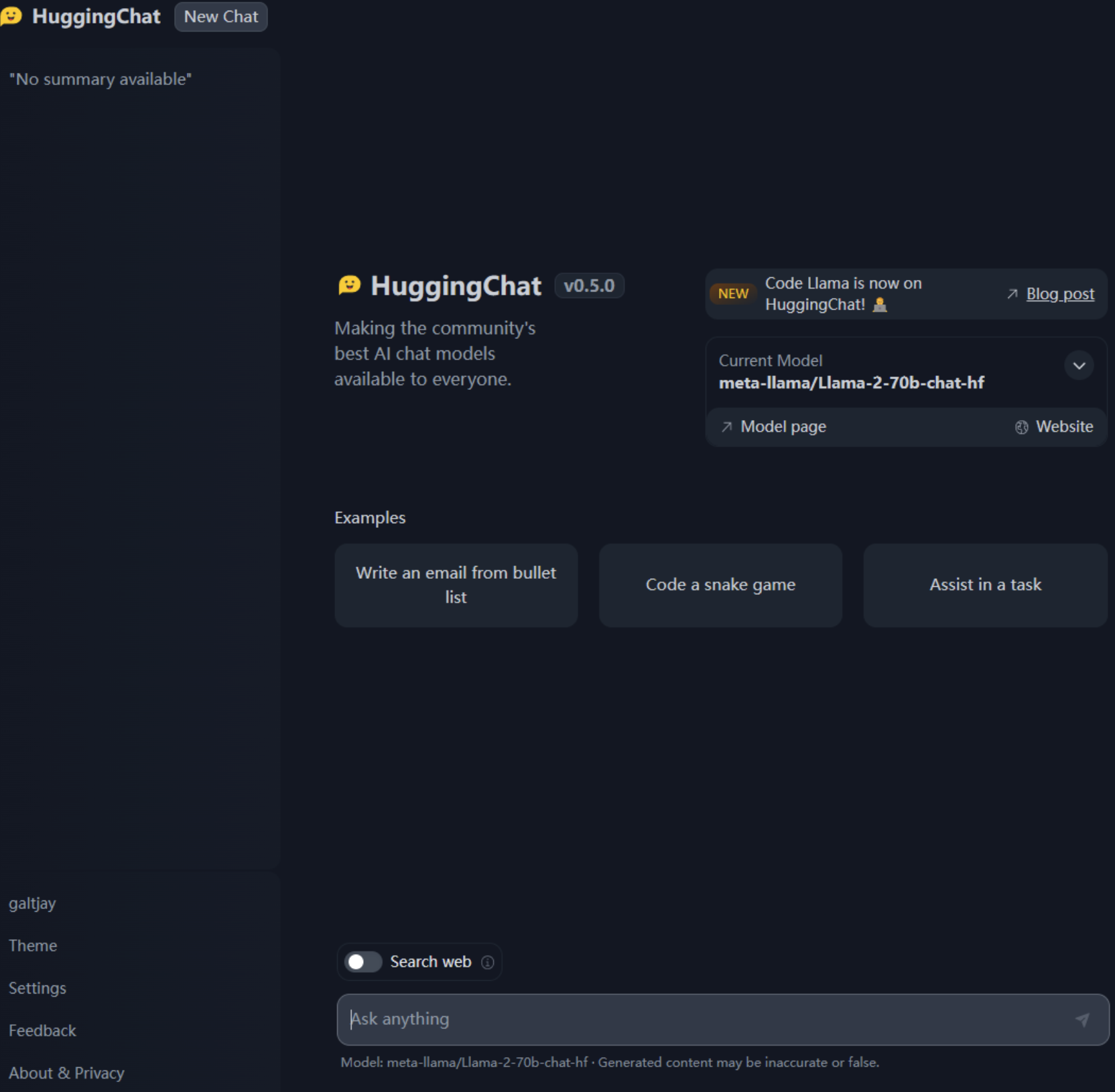
There isn't much to discuss about the frontend project, so let's proceed directly to the deployment:
This project relies on MongoDB to store session history, so let's start by setting up a MongoDB instance locally:
docker run -d -p 27017:27017 --name mongo-chatui mongo:latest
docker-compsoe:
version: '3'
services:
mongo-chatui:
image: mongo:latest
container_name: mongo-chatui
ports:
- "27017:27017"
Configuring and packaging the frontend project:
First, git clone https://github.com/huggingface/chat-ui.git
Navigate to the project folder chat-ui, where the core configurations are stored in the .env file. Create a copy of .env called .env.local for configuration modifications:
1. First, you need to make changes to the two most fundamental configurations:
MONGODB_URL=mongodb://localhost:27017
HF_ACCESS_TOKEN=hf_TiNiTzAUnMSyyBnXPKZfCXXXXYYYYYZZZZ
2. Modify the definition of models in MODELS, and here's an example configuration for local deployment based on text-generation-inference for your reference. The main addition is the 'endpoints' field:
{
"name": "stabilityai/stablecode-instruct-alpha-3b",
"endpoints":[{"url": "http://127.0.0.1:8080/generate_stream"}],
"datasetName": "stabilityai/stablecode-instruct-alpha-3b",
"description": "StableCode",
"websiteUrl": "https://huggingface.co/stabilityai/stablecode-instruct-alpha-3b",
"userMessageToken": "",
"assistantMessageToken": "",
"messageEndToken": "</s>",
"preprompt": "Below are a series of dialogues between various people and an AI assistant. The AI tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble-but-knowledgeable. The assistant is happy to help with almost anything, and will do its best to understand exactly what is needed. It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer. That said, the assistant is practical and really does its best, and doesn't let caution get too much in the way of being useful.\n-----\n",
"promptExamples": [
{
"title": "Write an email from bullet list",
"prompt": "As a restaurant owner, write a professional email to the supplier to get these products every week: \n\n- Wine (x10)\n- Eggs (x24)\n- Bread (x12)"
}, {
"title": "Code a snake game",
"prompt": "Code a basic snake game in python, give explanations for each step."
}, {
"title": "Assist in a task",
"prompt": "How do I make a delicious lemon cheesecake?"
}
],
"parameters": {
"temperature": 0.9,
"top_p": 0.95,
"repetition_penalty": 1.2,
"top_k": 50,
"truncate": 1000,
"max_new_tokens": 1024
}
}
3. Some other configurations:
You can adjust the primary color scheme of the page, project name, and internal hyperlinks.
You can configure local, OpenID, and third-party authentication, among other options.
After configuring:
Run
npm installto install dependencies.Use
npm run devto locally test the application.If everything is working fine, run
npm run buildto create a build.Deploy the contents of the
/builddirectory to an nginx server.
Additional parameters' explanations:
Temperature:
Purpose: Temperature parameter affects the diversity of generated text.
Explanation: Higher temperature values (greater than 1.0) increase the randomness of text generation, making the output more diverse. Lower temperature values (less than 1.0) reduce randomness, resulting in more deterministic and consistent text.
Example: A higher temperature (e.g., 0.9) might generate different outputs, including less common words or phrases, while a lower temperature (e.g., 0.2) might produce more common and predictable text.
Top_p (Top probability):
Purpose: Controls the probability distribution of words in generated text.
Explanation: The top_p parameter represents the highest probability words considered by the model when generating text. It dynamically selects words with cumulative probabilities less than or equal to top_p to generate text, helping to avoid generating unreasonable or irrelevant text.
Example: Setting top_p to 0.95 makes the model consider only the top 95% of words with the highest cumulative probabilities, enhancing the coherence and rationality of the text.
Repetition Penalty:
Purpose: Controls the extent of punishment for repeated words in generated text.
Explanation: The repetition_penalty parameter is used to reduce repeated words in generated text. Higher values (greater than 1.0) increase the penalty, encouraging more diverse text. Lower values (less than 1.0) reduce the penalty, allowing some word repetition in the text.
Example: Setting repetition_penalty to 1.2 reduces the frequency of repeated words in the generated text, increasing text diversity.
Top_k (Top words):
Purpose: Limits the number of words considered in generated text.
Explanation: The top_k parameter specifies that the model will only consider the top k words with the highest probabilities in the distribution, ignoring other words. This can be used to restrict the vocabulary diversity and complexity in generated text.
Example: Setting top_k to 50 makes the model consider only the top 50 words with the highest probabilities, ignoring other words.
Truncate (Length truncation):
Purpose: Limits the length of generated text.
Explanation: The truncate parameter restricts the total length of generated text. If the generated text exceeds the specified truncation length, the model truncates the text to ensure it doesn't become too long.
Example: Setting truncate to 1000 ensures that the total length of the generated text does not exceed 1000 tokens (such as words or subwords).
Max_new_tokens (Maximum new tokens):
Purpose: Limits the number of newly generated tokens in the text.
Explanation: The max_new_tokens parameter is used to control the number of newly generated tokens in the text, ensuring that the generated text does not become overly long. It is typically used to manage the text's length.
Example: Setting max_new_tokens to 1024 limits the number of newly generated tokens in the text to no more than 1024.