
有句非洲谚语非常著名:“一个人可以走得很快,而一群人才能走得更远。”这句话传达了团队合作的重要性,强调了分工明确和协同合作的力量。正如这句话所示,只有在团队成员各尽其职、共同努力时,才能真正取得成功。
这个理念同样适用于大型语言模型(LLM)。我们不必期望一个单一的 LLM 能够处理所有复杂的任务。相反,我们可以将不同的 LLM 或 AI Agent 组合在一起,让每个 Agent 专注于其擅长的特定领域。这种安排能显著提升整体系统的效率和效果。
通过这种方式构建的系统不仅更加稳健,还能生成更高质量的成果,最终得出的结果也更为可靠。
系统整体工作流程
在进入编码部分之前,我们需要清晰理解本文所构建系统的主要组成部分。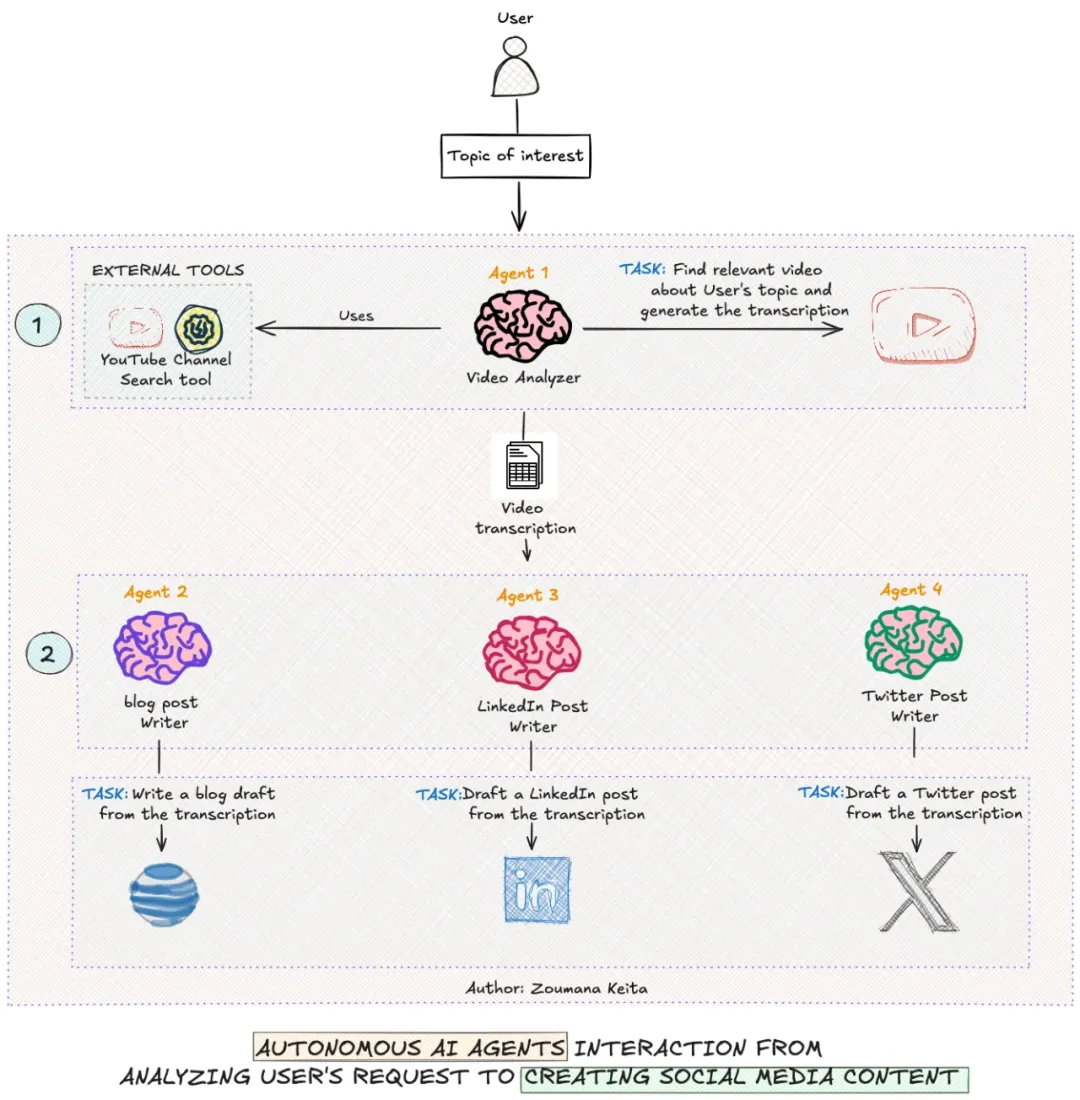
自主 AI Agent 工作流程由四个专门技能的 Agent 组成:
- 首先,用户的请求被提交到系统。
- Agent 1 或视频分析器在互联网上执行深入研究,利用 YouTube 频道搜索等外部工具查找与用户请求相关的信息,并将结果传递给下一个 Agent 进行进一步处理。
- Agent 2 或博客文章撰写者使用前一个 Agent 的结果撰写一篇全面的博客文章。
- 类似地,Agent 3 和 Agent 4 分别生成吸引人的 LinkedIn 帖子和推文。
- Agent 2、Agent 3 和 Agent 4 的响应会被保存到不同的 Markdown 文件中,以供最终用户使用。
为什么我们要关注 AI Agent 而不是单个 LLM?
这里所提到的任务是一个整体任务,要求 LLM 完成单一目标,如数据提取。这种方法在处理更复杂、多步骤的任务时的局限性愈加明显,以下是其中的一些局限性:
- 任务执行的灵活性:单个提示的 LLM 需要为每个任务精心设计提示,而当任务需求变化时,更新这些提示将变得繁琐。相比之下,AI Agent 能够将复杂性分解为子任务,并适应任务的变化,而不需要在提示工程上耗费大量精力。
- 任务的连续性与上下文保留:单个提示的 LLM 可能会在对话中丢失重要上下文,因为它们主要在单个交互回合的限制内运行。AI Agent 则能够在不同的互动之间保持上下文,每个 Agent 可以参考前一个 Agent 的响应来完成其任务。
- 专业化与协作:尽管经过大量微调的 LLM 可能具备特定领域的知识,但这种方式既耗时又昂贵。AI Agent 则可以设计为一个由多个专门模型组成的团队,每个模型专注于特定的任务,例如研究、博客撰写和社交媒体管理。
- 互联网访问:单个 LLM 通常依赖于预定义的知识库,信息更新不及时可能导致错误或信息有限。而 AI Agent 能够实时访问互联网,提供更为准确的信息,从而确保更好的决策能力。
构建内容创建工作流程
在本节中,我们将探讨如何利用智能体工作流程创建一个系统,在对用户主题进行深入研究后,撰写博客文章、LinkedIn 内容和 Twitter 帖子。代码结构如下图所示:
project
|
|---Multi_Agents_For_Content_Creation.ipynb
|
data
|
|---- blog-post.md
|---- linkedin-post.md
|---- tweet.md
project文件夹是根目录,包含data文件夹和 notebook。data文件夹目前为空,但在整个工作流程执行后应该包含以下三个 Markdown 文件:blog-post.md、linkedin-post.md和tweet.md。- 每个 Markdown 文件都包含相应 Agent 完成任务的结果。
Agent 的创建及其角色与任务
现在我们已经了解了每个 Agent 的角色,接下来将探讨如何实际创建它们,以及它们的具体角色和任务。在此之前,我们需要设置一些前提条件,以便更好地实现这些角色和任务。
前提条件
代码将在 Google Colab notebook 中运行,我们的用例仅需安装两个库:openai 和 crewai[tools],可以通过以下方式安装它们:
%%bash
pip -qqq install 'crewai[tools]'
pip -qqq install youtube-transcript-api
pip -qqq install yt_dlp
成功安装库后,接下来是导入必要的模块:
import os
from crewai import Agent
from google.colab import userdata
from crewai import Crew, Process
from crewai_tools import YoutubeChannelSearchTool
from crewai import Task
每个 Agent 都利用 OpenAI 的 GPT-4o 模型,我们需要通过以下方式设置访问模型的权限:
OPENAI_API_KEY = userdata.get('OPEN_AI_KEY')
model_ID = userdata.get('GPT_MODEL')
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
os.environ["OPENAI_MODEL_NAME"] = model_ID
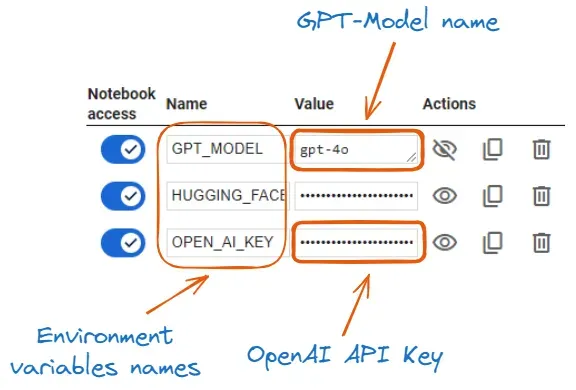 环境变量及其值
环境变量及其值
- 首先,我们使用内置的
userdata.get函数从 Google Colab Secrets 中获取OPEN_AI_KEY和GPT_MODEL。 - 然后,我们用
os.environ函数设置OPEN AI KEY和GPT-4o模型。 - 在完成上述两步后,使用该模型创建 Agent 应该不会有任何问题。
Agent 及其角色
通过 Agent 类,我们可以通过提供以下属性来创建一个 Agent:role、goal、backstory 和 memory。
只有 Agent 1 或视频分析器具有额外的属性:tools 和 allow_delegation。
大多数属性都是自解释的,但我们还是来了解它们的具体意义。
role类似于职位名称,定义了 Agent 的具体角色,例如 Agent 1 的角色是主题研究员。goal指明 Agent 角色的具体目标。backstory进一步细化 Agent 的角色,使其更加具体。memory属性为布尔值。设置为 True 则允许 Agent 记住、推理并从过去的互动中学习。tools是 Agent 执行任务时使用的工具列表。allow_delegation是布尔值,表示 Agent 的结果是否必须交给其他 Agent 进一步处理。
现在,让我们开始创建所有 Agent。
在此之前,我们设置必须由第一个 Agent 使用的工具,以探索我的个人 YouTube 频道。
这是通过提供句柄 @techwithzoum 的 YoutubeChannelSearchTool 类实现的。
# The tool used by the topic researcher
youtube_tool = YoutubeChannelSearchTool(youtube_channel_handle='@techwithzoum')
- Agent 1 — 主题研究员
topic_researcher = Agent(
role='Topic Researcher',
goal='Search for relevant videos on the topic {topic} from the provided YouTube channel',
verbose=True,
memory=True,
backstory='Expert in finding and analyzing relevant content from YouTube channels, specializing in AI, Data Science, Machine Learning, and Generative AI topics.',
tools=[youtube_tool],
allow_delegation=True
)
- 我们首先将该 Agent 的角色定义为主题研究员。
- 然后,我们要求 Agent 使用提供的
{topic}查找相关视频。 - 最后,我们将第一个 Agent 定义为使用 YouTube 搜索工具查找和分析关于 AI、数据科学、机器学习和生成式 AI 主题的相关内容的专家。
在当前 Agent 定义中,后续 Agent 的定义与此相似,属性值有所不同。一旦理解了这一点,后续 Agent 的定义就不再需要详细解释。
- Agent 2 — 博客撰写者
blog_writer = Agent(
role='Blog Writer',
goal='Write a comprehensive blog post from the transcription provided by the Topic Researcher, covering all necessary sections',
verbose=True,
memory=True,
backstory='Experienced in creating in-depth, well-structured blog posts that explain technical concepts clearly and engage readers from introduction to conclusion.',
allow_delegation=False
)
- Agent 3 — LinkedIn 帖子创建者
# LinkedIn Post Agent
linkedin_post_agent = Agent(
role='LinkedIn Post Creator',
goal='Create a concise LinkedIn post summary from the transcription provided by the Topic Researcher.',
verbose=True,
memory=True,
backstory='Expert in crafting engaging LinkedIn posts that summarize complex topics and include trending hashtags for maximum visibility.',
allow_delegation=False
)
- Agent 4 — Twitter 帖子创建者
twitter_agent = Agent(
role='Twitter Content Creator',
goal='Create a short tweet from the transcription provided by the Topic Researcher that capture key points and insights',
verbose=True,
memory=True,
backstory='Specializes in distilling complex information into concise, impactful tweets that resonate with a tech-savvy audience.',
allow_delegation=False
)
注意到最后三个 Agent 不再委托任务,这是因为它们的结果不需要被其他 Agent 处理。现在我们的 Agent 已经准备好了解对它们的期望,这是通过 Task 类来实现的。
任务
人类在接到任务指示后会执行任务来交付结果,Agent 也需要执行任务并交付结果,所需的属性如下:
description:需要 Agent 执行的任务的明确描述。描述越清晰,模型的输出就越好。expected_output:对 Agent 预期结果的文本描述。agent:执行特定任务的 Agent 占位符。tools:类似于角色定义部分,并非每个 Agent 都使用工具。在我们的用例中,只有主题研究员使用了工具。output_file:文件名及其格式。仅对需要将任务结果保存为文件的 Agent 指定,例如 Markdown 文件,博客撰写者的文件名可以是blog-post.md。
接下来,我们来看这些任务的 Python 实现。
- Agent 1 — 主题研究员
research_task = Task(
description="Identify and analyze videos on the topic {topic} from the specified YouTube channel.",
expected_output="A complete word by word report on the most relevant video found on the topic {topic}.",
agent=topic_researcher,
tools=[youtube_tool]
)
- Agent 2 — 博客撰写者
blog_writing_task = Task(
description=""" Write a comprehensive blog post based on the transcription provided by the Topic Researcher.
The article must include an introduction, step-by-step guides, and conclusion.
The overall content must be about 1200 words long.""",
expected_output="A markdown-formatted of the blog",
agent=blog_writer,
output_file='./data/blog-post.md'
)
- Agent 3 — LinkedIn 帖子创建者
linkedin_post_task = Task(
description="Create a LinkedIn post summarizing the key points from the transcription provided by the Topic Researcher, including relevant hashtags.",
expected_output="A markdown-formatted of the LinkedIn post",
agent=linkedin_post_agent,
output_file='./data/linkedin-post.md'
)
- Agent 4 — Twitter 帖子创建者
twitter_task = Task(
description="Create a tweet from the transcription provided by the Topic Researcher, including relevant hashtags.",
expected_output="A markdown-formatted of the Twitter post",
agent=twitter_agent,
output_file='./data/tweets.md'
)
对于每个 Agent,属性都是自解释的,结果如下:
- 第一个 Agent 生成的结果是供后三个 Agent 使用的原始文本数据。
- 第二个 Agent 的结果是一个名为
blog-post.md的 Markdown 文件。 - 第三个 Agent 的结果是一个名为
linkedin-post.md的 Markdown 文件。 - 最后一个 Agent 的结果也是一个名为
tweets.md的 Markdown 文件。
让 Agent 开始工作
最后,我们协调 Agent 团队,按如下方式执行任务:
my_crew = Crew(
agents=[topic_researcher, linkedin_post_agent, twitter_agent, blog_writer],
tasks=[research_task, linkedin_post_task, twitter_task, blog_writing_task],
verbose=True,
process=Process.sequential,
memory=True,
cache=True,
max_rpm=100,
share_crew=True
)
agents对应于所有 Agent 的列表。tasks是每个 Agent 需要执行的任务列表。- 我们将
verbose设置为 True,以查看完整的执行跟踪。 max_rpm是我们的团队为避免速率限制而每分钟最多可以执行的请求数。- 最后,
share_crew表示 Agent 共享资源来执行任务,意味着第一个 Agent 与其他 Agent 共享其响应。
在协调了 Agent 之后,是时候通过 kickoff 函数触发它们,该函数接收一个输入字典作为参数。我们搜索的是我录制的关于 GPT3.5 Turbo 微调与图形界面的一个视频。
topic_of_interest = 'GPT3.5 Turbo Fine-tuning and Graphical Interface'
result = my_crew.kickoff(inputs={'topic': topic_of_interest})
成功执行上述代码将生成我们之前指定的三个 Markdown 文件。
以下是每个文件内容的结果显示。作为录制视频的人,这些内容与教程中涉及的内容完全一致。
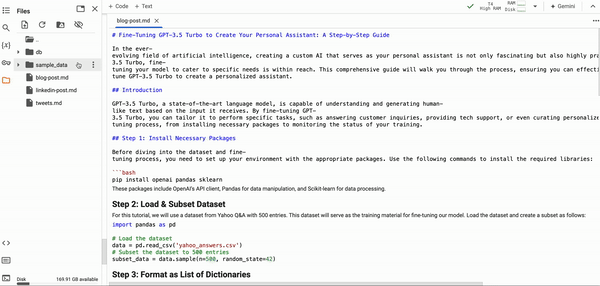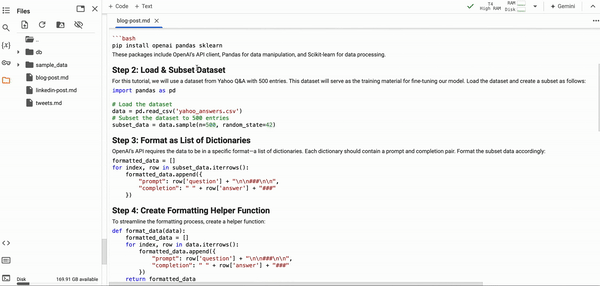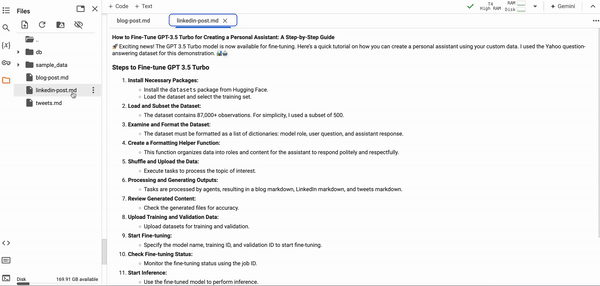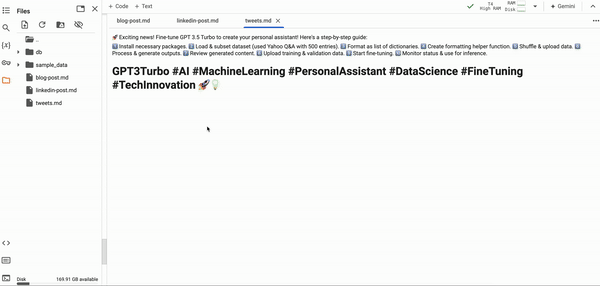
虽然博客 Agent 未能提供百分之百的分步指南,用户在执行代码时可能会遇到问题,但它提供了对教程范围的极好理解。
LinkedIn 和 Twitter 帖子的结果非常出色!
你可以在下面的链接中查看所有文件的内容:
https://github.com/keitazoumana/LLMs/tree/main/ai_agents_outputs
评估 Agent
上述对 Agent 的评估基于我对内容的个人熟悉程度。然而,在投产之前,需要更客观且可扩展的评估方法。以下是一些有效评估这些 AI Agent 的策略:
- 基准测试:可以用来评估每个 Agent 在不同任务上的表现,使用已建立的数据集如 GLUE 和 FLASK,进行与不同先进模型的标准化比较。
- 事实准确性测量:评估 Agent 在多个领域提供事实性回答的能力。
- 上下文感知相关性评分:量化 Agent 的响应与给定提示词的对齐程度。
可以利用多个框架来执行这些评估,其中包括:
- DeepEval:这是一个开源工具,用于量化 LLM 在不同指标上的性能。
- MMLU(大规模多任务语言理解):这是一个测试模型在零样本和单样本设置下的多学科知识的框架。
- OpenAI evals:也是一个用于评估 LLM 或任何基于 LLM 系统的框架。
总结
本文简要介绍了如何通过 AI Agent 有效完成高级任务,而不是让一个大语言模型单打独斗。