
端侧应用始终是大模型领域的热门话题。特别是在人形机器人盛行的背景下,“具身智能”再次引起了人们的关注,探索如何将大模型的强大能力与低功耗客户端设备相结合。对于端侧设备而言,网络连接的稳定性常常无法保证,且带宽受到限制,因此在云服务上使用大模型会面临不少挑战。此外,端侧设备在安全性和隐私问题上也需格外谨慎,因此选择本地运行显得尤为合理。
接下来,我们将介绍一个在树莓派上运行的大模型语音聊天机器人。该机器人采用“按键对讲”模式,用户只需按下按钮并讲话,机器人便会生成自然流畅的语音回答,而整个过程均在本地完成,无需联网。例如,用户可以问它:“你是如何生活的?”。
在硬件方面,你将需要:
- 4GB内存的树莓派4(树莓派3也可行,只要内存足够)
- 一个USB麦克风(树莓派本身不配备麦克风)
- 喇叭,可以使用USB喇叭,这里采用的是带有喇叭的HDMI显示屏,因此通过HDMI输出音频
- 一个普通的2线按钮,连接方式为一条线接到按钮,另一条接到地线,这里使用的是从Google AIY VoiceKit拆下来的按钮,将BTN线(Pin 3)连接到树莓派的GPIO 8,GND线(Pin 1)连接到GPIO 6。
按钮连线请参考:
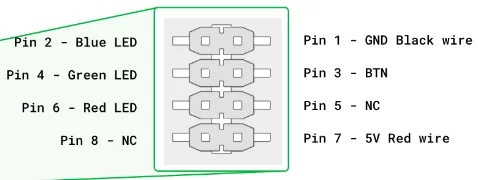
详细接线图可见:Google AIY VoiceKit 按钮连接引脚图
连接完成后,设备的样子大致如下:

主要软件组件包括三个部分:
- 语音识别:采用主动语音识别(ASR),将用户的语音转化为文字请求,这里使用的是whisper.cpp(OpenAI Whisper的C++实现)
- 大语言模型:根据用户的请求生成回答文本,这里使用的是TinyLlama 1.1B(已用llamafile包装成ARM64可执行文件)
- 语音合成:采用文本转语音(TTS)技术,将LLM的回答合成为语音,这里使用的是piper
树莓派运行的操作系统为Ubuntu server for Raspberry Pi,用户可以从以下链接下载预装好的映像:
当用户按下按钮时,GPIO8的状态会发生变化,树莓派随即开启麦克风录制用户的语音,直到用户松开按钮(临时录音文件保存在本地)。接着,whisper.cpp会把录音转化为文字,并将其作为提示输入给TinyLlama,随后TinyLlama生成的回答通过piper转化为语音进行播放。
虽然树莓派4能够运行TinyLlama 1.1B,内存充足,但其生成速度仍显缓慢,约为每秒生成4到5个token。因此,如果回答较长,用户可能需要等待较长时间才能得到回应,影响了用户体验。为了改善这一情况,我们采取了以下措施:1)在系统提示中告知LLM限制回答字数;2)采用流式输出,每生成一个完整句子便调用piper进行语音合成,从而减少用户的等待时间。